




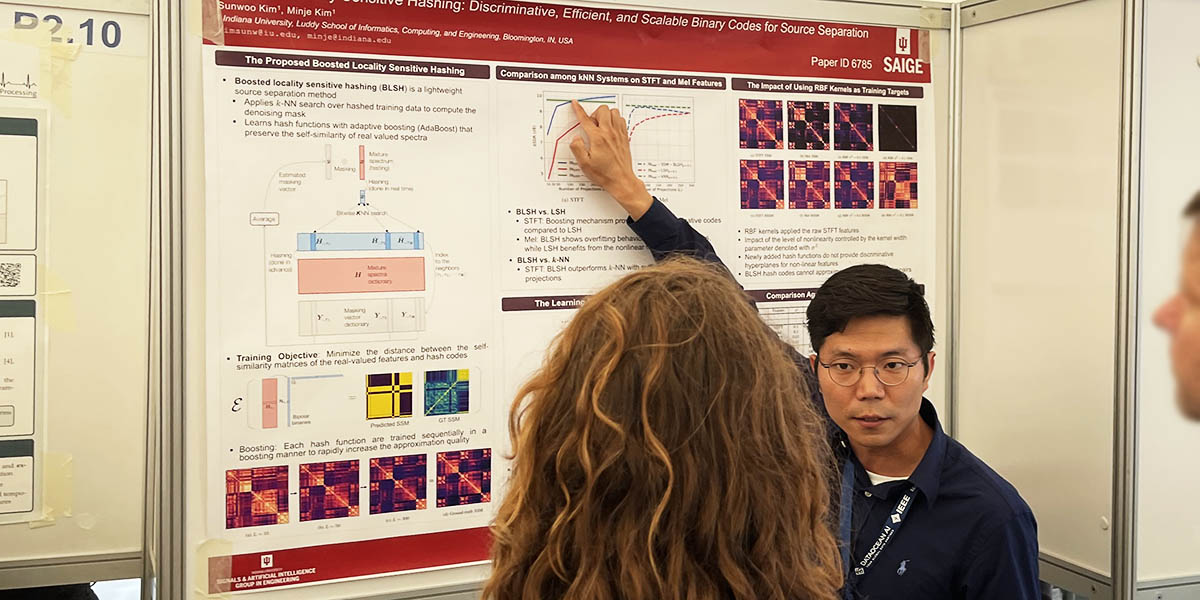
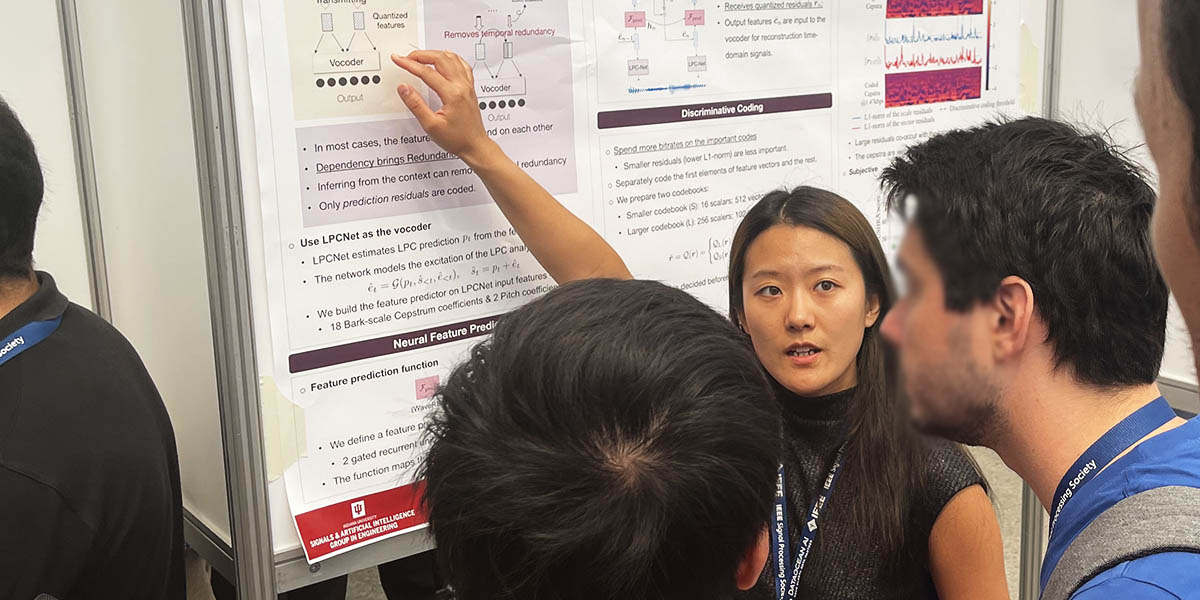



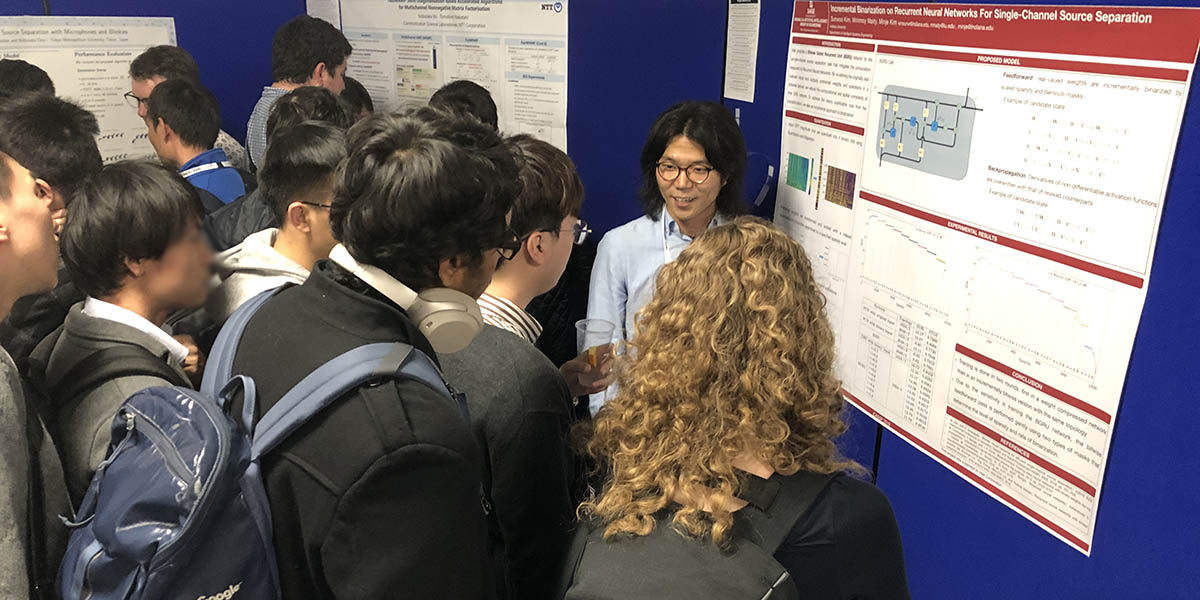
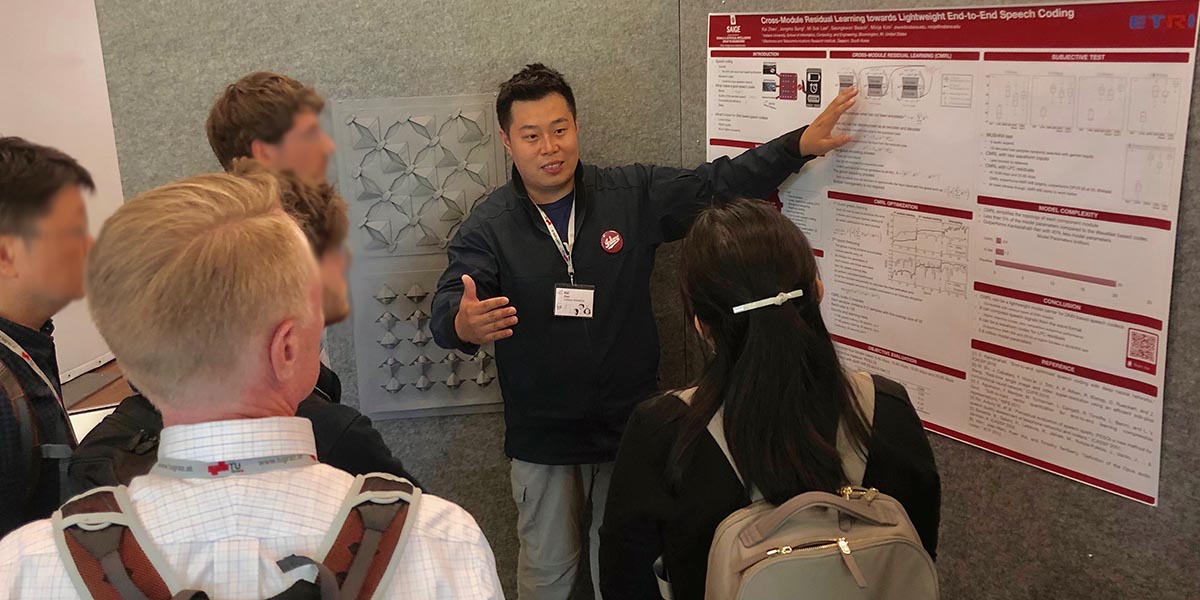



We live in a world full of complex problems. For an AI system to solve them, it involves a complex model that can best approximate the problem. In this era of AI, we finally seem to afford those complex models thanks to the technological advances in computing power, the theoretical advances in machine learning algorithms, and the availability of big data. As a result, AI starts to compete with human intelligence in some problems.
However, we believe that AI is still missing many powerful features that natural intelligence surely possesses. For example, does your brain need ten times more sugar intake when it solves a problem ten times more difficult? How much energy does a mosquito need to sense the target and fly to the destination accordingly? Can you imagine a mosquito-sized drone that can do the same job (with a tiny battery)? We know that the intelligent systems found in nature are not only effective but efficient. One of the main research agendas in SAIGE is building machine learning models that run more efficiently during the test time and in hardware. This kind of system ranges from a deep neural network and probabilistic topic models defined in a bitwise fashion to using psychoacoustics to make a simple model more powerful.
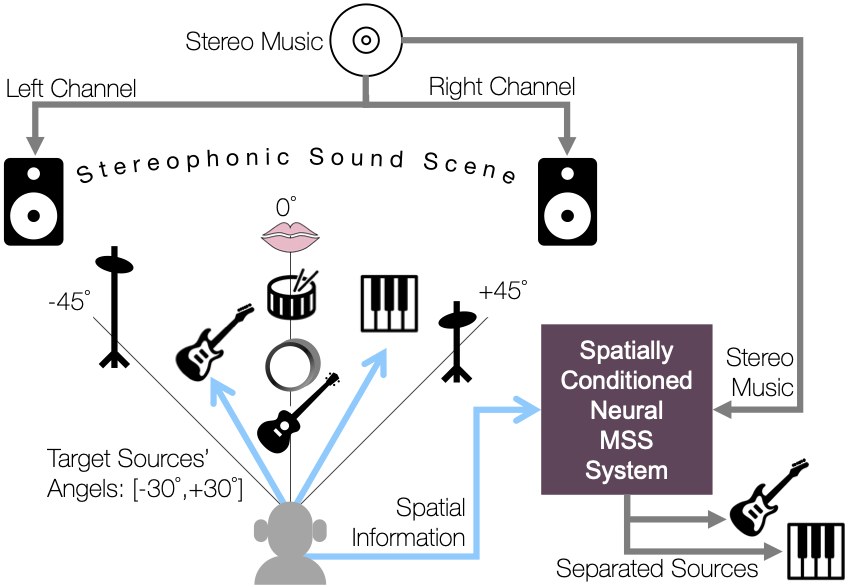
Another important intelligent behavior is a collaboration among individuals. We seek collaboration between devices and sensors like we do in team projects. For example, we have been interested in consolidating many different audio signals recorded by various devices to come up with a commonly dominant source of the audio scene. Since the recordings can contain both the dominant source of interest and its own artifact (e.g. additive noise, reverberation, band-pass filtering, etc), a naïve average of the recordings is not a good solution to this problem. We call this kind of problem collaborative audio enhancement. Another collaboration in nature can happen between different sensors like we recognize someone else’s emotion by looking at her facial expression and listening to her voice. Therefore, building a machine learning model that fuses all the different decisions made from multiple modalities is of our interest, too.
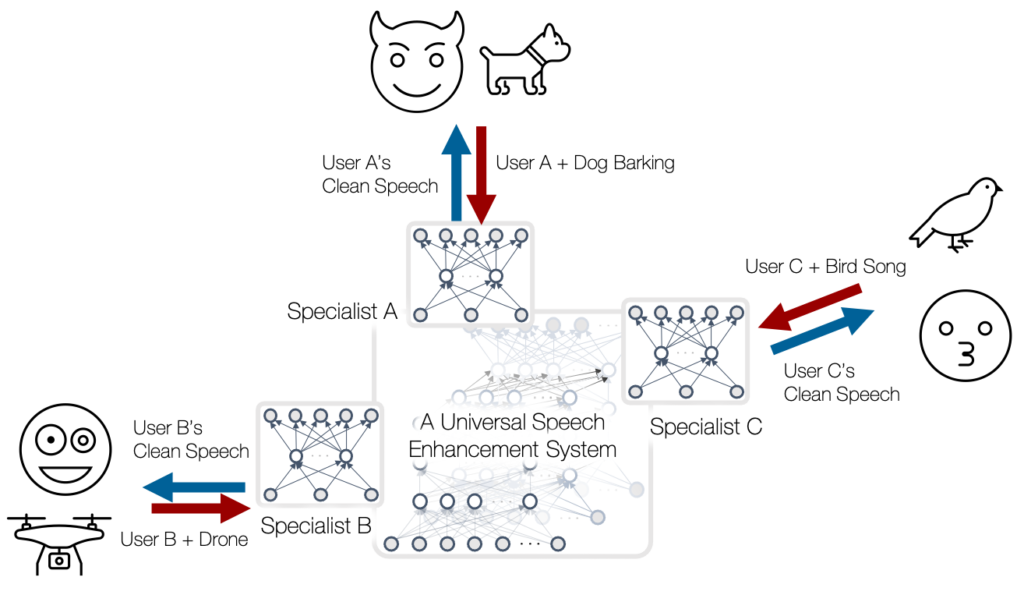
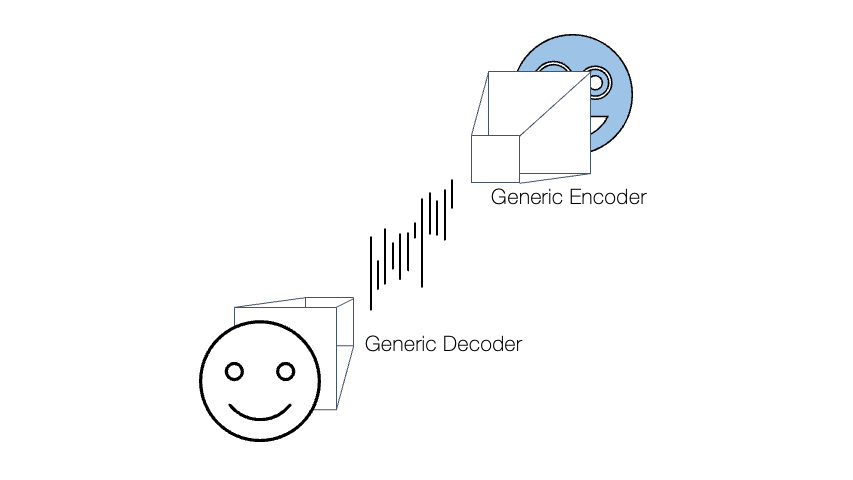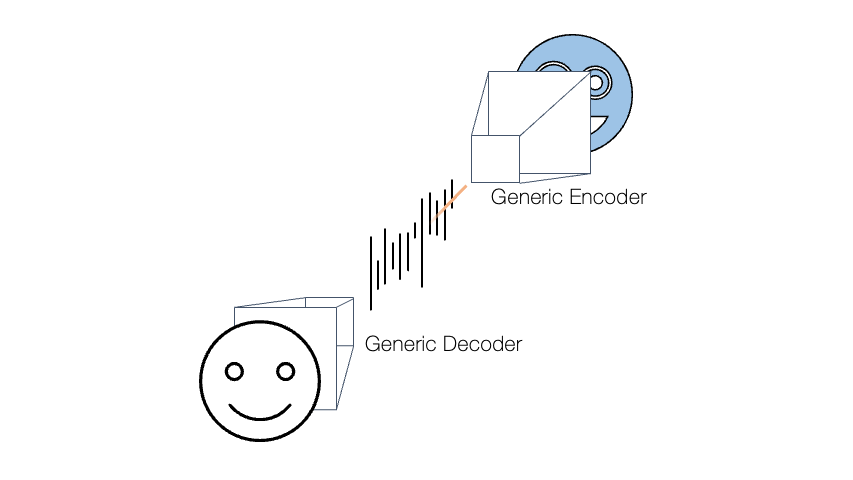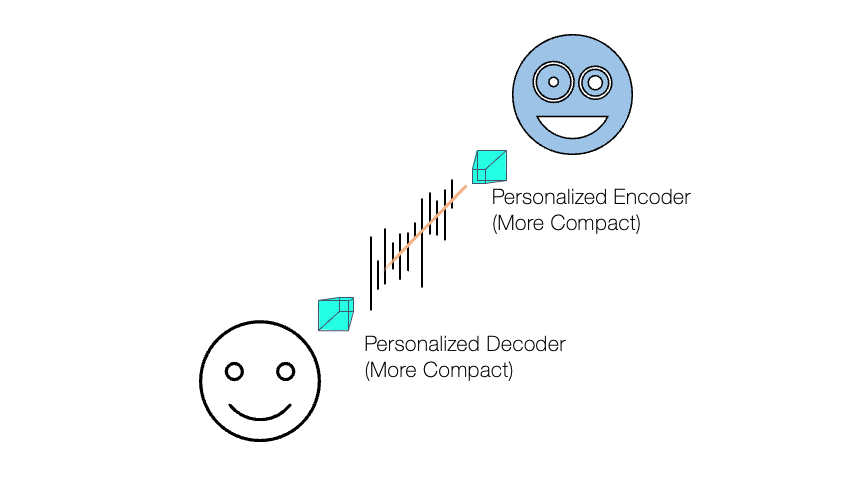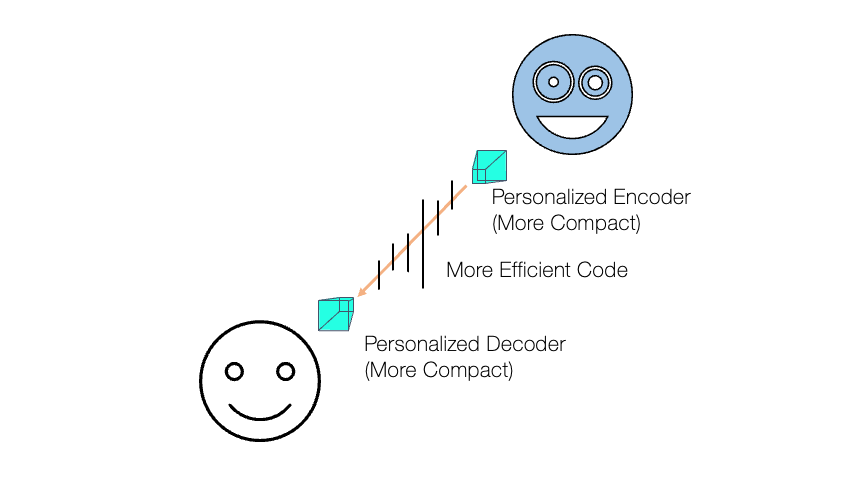
Finally, we believe that one of the keys to success in machine learning applications is to improve each user’s personal experience using personalized models. A personalized model can be a more resource-efficient solution than a general-purpose model, too, because it focuses on a particular sub-problem, for which a smaller model architecture can be good enough. However, training a personalized model requires data from the particular test-time user, which are not always available due to their private nature. Furthermore, such data tend to be unlabeled as it can be collected only during the test time, once after the system is deployed to the user devices. One could rely on the generalization power of a generic model, but such a model can be too computationally/spatially complex for real-time processing in a resource-constrained device. Our machine learning models will require no or few data samples from the test-time users, while they can still achieve the personalization goal. Likewise, our personalized models are designed to minimize the use of personal data to improve the privacy preservation in machine learning as well as the performance imbalance between different social groups.