(For a more general introduction to the personalized speech enhancement (PSE) project, please visit the overview page.)
Imagine a small speech enhancement model deployed to a resource-constrained device. Its limited generalization power caps its enhancement performance, even though it was trained from a large dataset of noisy speech covering all sorts of human speech variations and additive noise sources. While the small model does its best for speech enhancement, it also realizes that there is only a small number of people, or even just one person, who keeps using the model. The small model feels that it could actually do better than what it can currently do, because the enhancement task isn’t that big considering the reduced problem. This scenario isn’t uncommon, especially when it comes to a small personal device owned by a single user.
However, the small model cannot improve by itself because it was after the model was deployed to the test environment. In other words, the model is exposed to many hours of noisy speech environments, while there is no ground-truth clean speech available as the target of the model’s output. What should the small model do to overcome this limitation?
The scenario falls into the category of zero-shot learning. There is potentially an unlimited amount of noisy recordings of the test scene, although they are not labeled with the corresponding clean speech. We formulate this problem using the student-teacher relationship, which was initially proposed by Hinton et al.1 in the classification context.
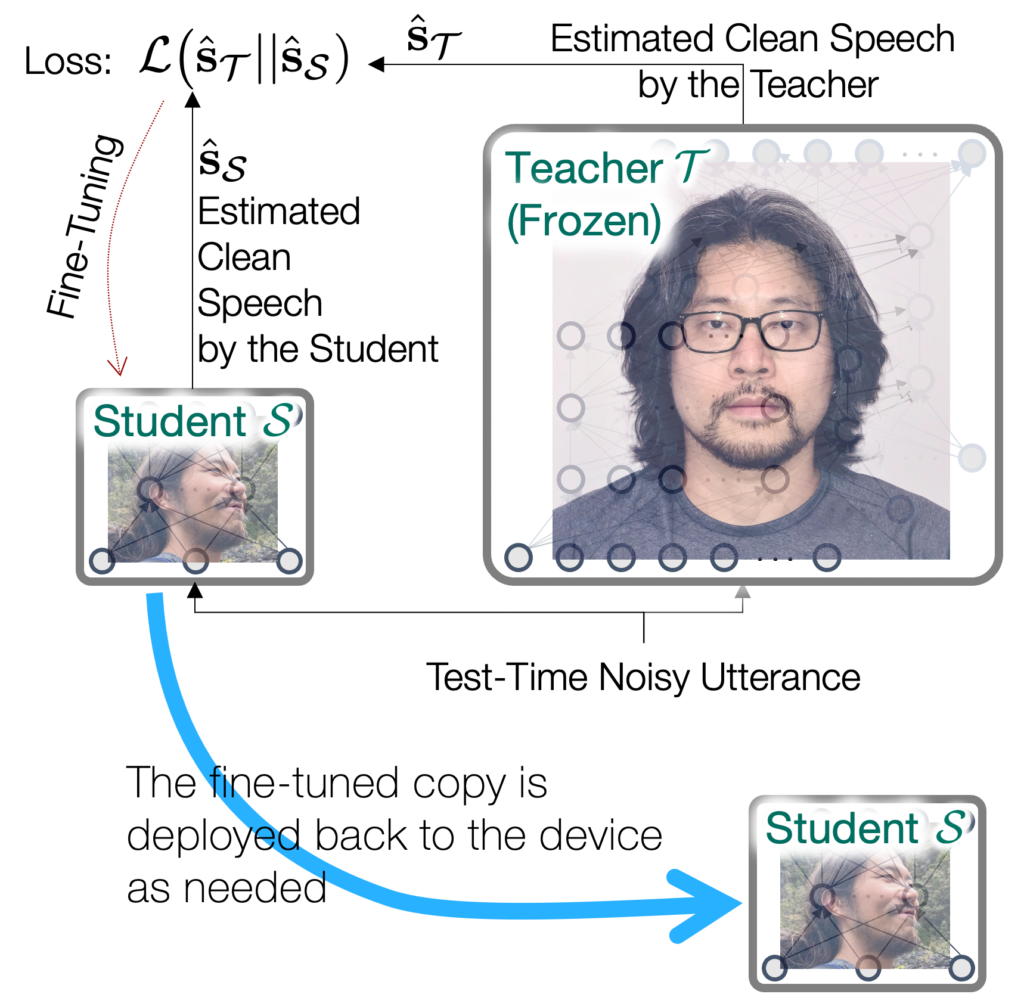
For PSE, we assume that there is a student model  , which is small and incapable of learning on its own. Meanwhile, we also posit that there exists a teacher model
, which is small and incapable of learning on its own. Meanwhile, we also posit that there exists a teacher model  , which is large enough to learn from a big dataset of various speakers and noise sources. The fundamental assumption here, therefore, is that the teacher must be better than the student, although the teacher might not be perfect. Formally, we can write
, which is large enough to learn from a big dataset of various speakers and noise sources. The fundamental assumption here, therefore, is that the teacher must be better than the student, although the teacher might not be perfect. Formally, we can write
![\[\mathcal{L}(\mathcal{S}(\mathbf{x})||\mathbf{s}) > \mathcal{L}(\mathcal{T}(\mathbf{x})||\mathbf{s}),\]](https://minjekim.com/wp-content/ql-cache/quicklatex.com-4eea77385d39f7b596f841681b9b10ff_l3.png "Rendered by QuickLaTeX.com")
 stands for the unknown ground-truth clean speech of the input noisy utterance
stands for the unknown ground-truth clean speech of the input noisy utterance  , given a loss function
, given a loss function  . In other words, we assume that the predicted clean speech by the teacher
. In other words, we assume that the predicted clean speech by the teacher  is closer to than
is closer to than  is.
is.
Based on this assumption, we can set up a zero-shot, test-time finetuning process. The student model observes a new test-time noisy speech utterance, and processes it to produce  . Then, instead of the unknown ground-truth clean speech , it’s compared with the teacher’s enhancement result
. Then, instead of the unknown ground-truth clean speech , it’s compared with the teacher’s enhancement result  , which can be considered as a pseudo-target. Now, the comparison results in a loss value
, which can be considered as a pseudo-target. Now, the comparison results in a loss value  , which is used to update the model parameters of .
, which is used to update the model parameters of .
The update should be scheduled carefully depending on the device’s resource constraints. For example, the device can keep the large teacher model in its storage, and performs this knowledge distillation-based update only when it’s plugged in or during the idle time. Or, the noisy recordings can be sent over to the cloud, where the teacher model and a copy of the student model reside. In the cloud computing scenario, the model parameters can be downloaded to the student model when it needs updates.
This highly adaptive KD approach shows powerful and robust improvement over a generic student model trained without knowing the test-time context. Meanwhile, since it doesn’t require any clean speech data from the users, it is convenient to implement (who wants to record their clean voice and share it with the third-party service provider?).
WASPAA 2021 Paper
Sunwoo Kim and Minje Kim, “Test-Time Adaptation Toward Personalized Speech Enhancement: Zero-Shot Learning With Knowledge Distillation,” in Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, Oct. 17-20, 2021 [pdf].
Audio Samples (from the WASPAA 2021 version)
The small GRU student model (2×32)
The large GRU student model (2×256)
Source Codes (WASPAA 2021)
https://github.com/kimsunwiub/PSE_ZeroShot_KD
Video Presentation (WASPAA 2021)
JASA Paper
Collaboration with Amazon Lab126 researchers, the project was extended to more challenging use cases, including joint denoising and dereverberation and a listening test. Please check out my recent journal article published at JASA for more details.
Sunwoo Kim, Mrudula Athi, Guangji Shi, Minje Kim, and Trausti Kristjansson, “Zero-Shot Test-Time Adaptation Via Knowledge Distillation for Personalized Speech Denoising and Dereverberation,” Journal of Acoustical Society of America, Vol. 155, No. 2, pp 1353-1367, Feb. 2024 [pdf]
※ The material discussed here is partly based upon work supported by the National Science Foundation under Award #: 2046963. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
- G. Hinton, O. Vinyals, and J. Dean, “Distilling the Knowledge in a Neural Network,” NIPS 2014 Deep Learning Workshop, arXiv.1503.02531[↩]