Crowdsource your recording job!

Such as in crowdsourcing, the project aims to improve the quality of the recordings from audio scenes, e.g. music concerts, talks, lectures, etc, by separating out the only interesting sources from multiple low-quality user-created recordings. This could be seen as a challenging microphone array setting with channels that are not synched, defected in unique ways, with different sampling rates.�
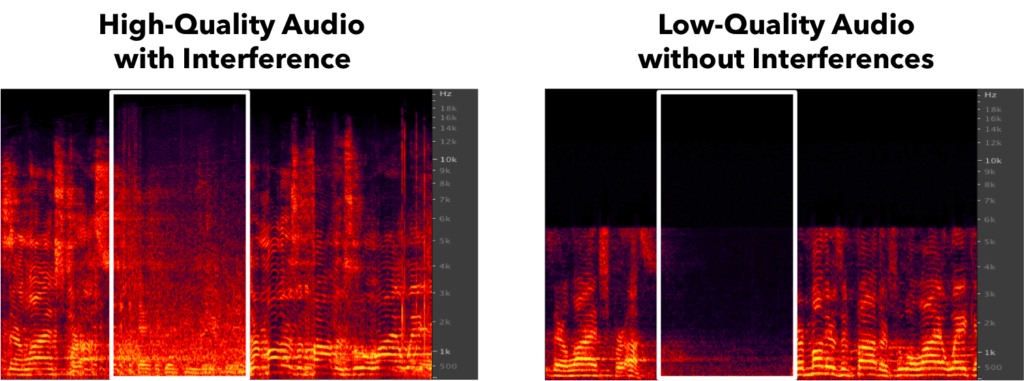
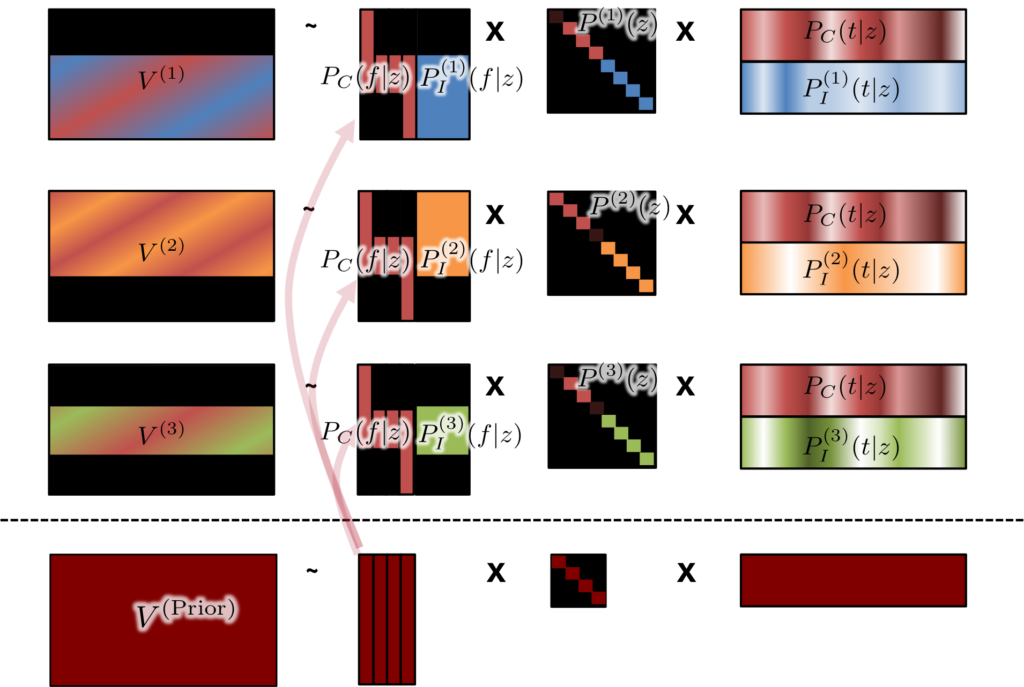
We achieve the separation by using an extended probabilistic topic model that enables sharing of some topics (sources) across the recordings. To put it another way, we do the usual matrix factorization for each recording, but fix some of the sources to be the same (with different global weights) across the simultaneous factorizations for all recordings.�
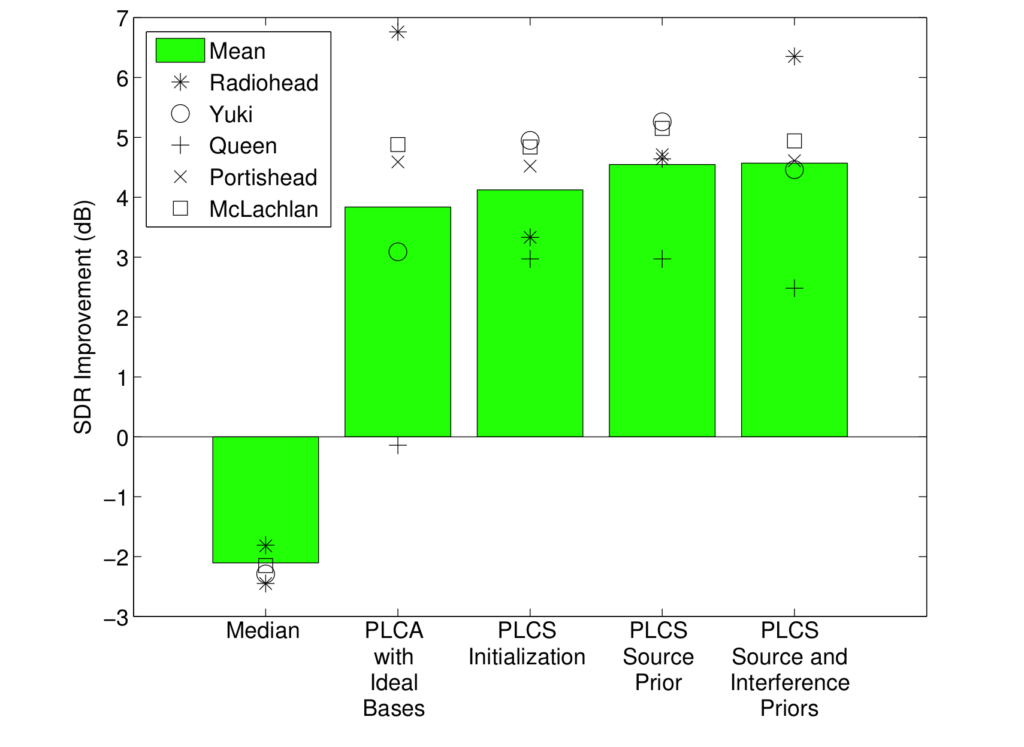
We could get better separation from some synthetic concert recordings than the oracle matrix factorization results with ideal bases pre-learned from the ground truth clean recording. Check out our award-winning paper about this project1.
1,000 Recordings
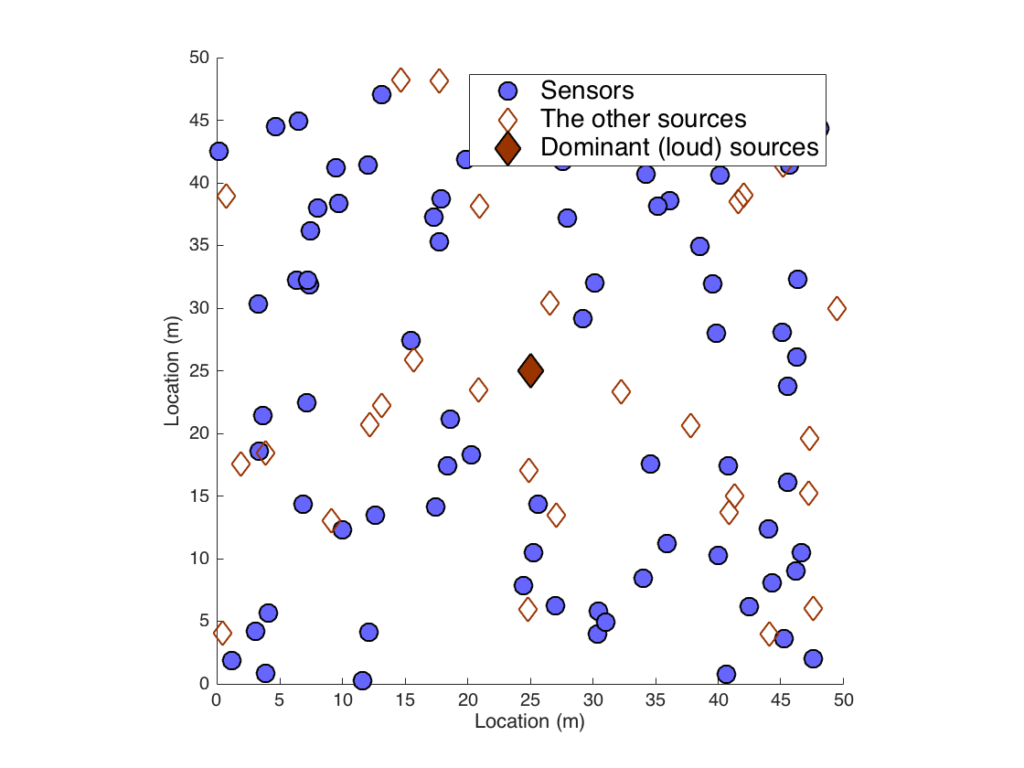
In the second phase of this project, we expanded our experiments into the case with a lot more microphones involved (1,000 sensors in the scene, the blue dots in the picture above). Now the goal is to extract the dominant source (filled diamond in the middle of the picture) out of those 1000 recordings. If this job is done manually, someone has to listen to all the 1000 recordings, and pick out the best one based on his or her perceptually quality assessment, which is a tedious, difficult, and expensive job to do. The selection will give the results ranging from the worst recording to the best one. Note that in the worst recording, someone else’ voice was recorded loudly rather than the dominant source of interest.
Once again, we want to achieve the separation by using an extended probabilistic topic model that enables sharing of some topics (sources) across the recordings. However, this procedure calls for a lot of computation on all the 1000 different recordings at every EM update. First, it is not very efficient particularly if there are too many recordings to deal with (we’re talking about an ad-hoc microphone array where the potential number of sensors is as many as the number of people in the crowd). Second, most of those recordings that are far from the dominant source of interest or the ones with severe artifacts don’t really contribute to the reconstruction of the source of interest anyway. Therefore, paying attention to those far-away / low-quality recordings is a waste of computation.�
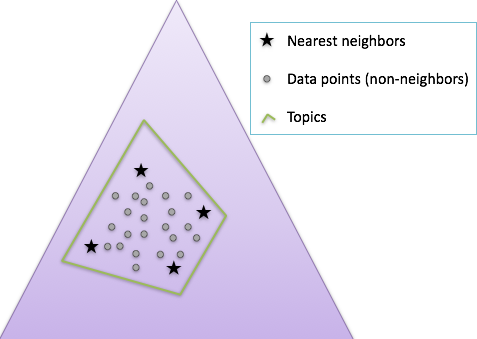
Our idea to get round this computational complexity issue is to focus on the nearest neighbors at every EM rather than the whole. In the figure above, we can see that topic modeling can find similar convex hulls (the green polytope wrapping the data points) whether or not we have those non-neighboring data samples during the process. Actually, what we believe is that focusing on those neighbors of current topics (corners of the polytope) will give us not only the speed-up, but the better results, because otherwise M-step spends a lot of time extracting out a small amount of contribution from those non-neighboring observations.
The nearest neighbor search can take much time though. If we do this search in an exhaustive way, something based on a proper distance metric, such as cross entropy between the normalized magnitude spectrograms of recordings and that of the reconstructed source, the overhead introduced by the search will diminish the speed-up. Instead, we can do this search based on Hamming distance calculated from hash codes of those spectrograms, because calculating Hamming distance can be done in a cheaper way by using the bitwise operations. If we find 3K pseudo neighbors with respect to Hamming distance in the first place, and then perform the exhaustive search only on the 3K candidates rather than the whole, we can construct the K-neighbor set in a fast way.
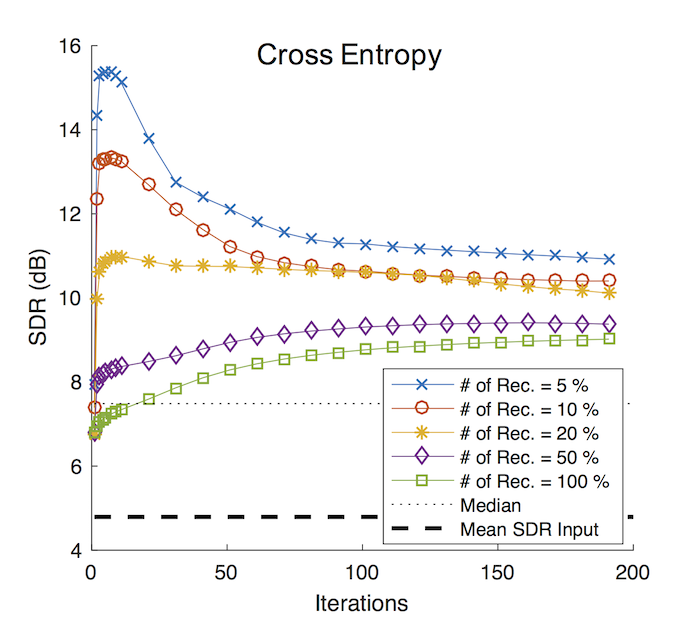
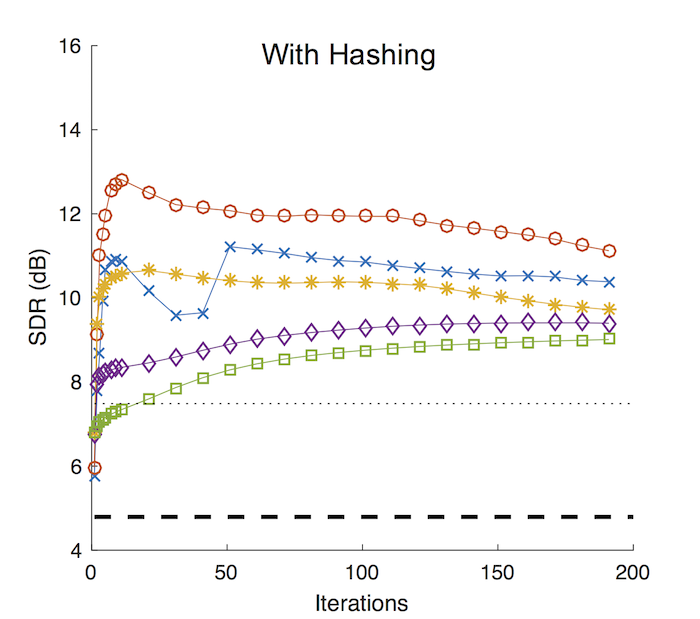
Indeed, when we do the EM updates only on those K-neighbors with an adequate choice of K (5 to 20% of the total number of recordings, blue, red and orange lines in the “Cross Entropy” case), we can get better separation performances than the full component sharing topic model (green line in the picture). This first experiment is with the cross entropy as the distance measure (more specifically, the divergence measure). The next one “With Hashing” case shows the proposed two-stage procedure, where we find 3K candidate neighbors using hashing in the first round, and then narrow down to the actual neighbors using cross entropy at the second round. Except the hiccups with the 5% case (blue line), where we use too small number of recordings, we can say that the two-stage method gives almost as good performance as the comprehensive search with cross entropy only.�
Check out how they sound!
Please check out our papers about this project, too2
※ This material is based upon work supported by the National Science Foundation under Grant: III: Small: MicSynth: Enhancing and Reconstructing Sound Scenes from Crowdsourced Recordings. Award #:1319708
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation
- Minje Kim and Paris Smaragdis, “Collaborative Audio Enhancement Using Probabilistic Latent Component Sharing,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Vancouver, BC, Canada, May 26-31, 2013 [pdf, bib]
<Google ICASSP Student Travel Grant>
<Best Student Paper in the Audio and Acoustic Signal Processing (AASP) area>[↩] - Minje Kim and Paris Smaragdis, “Efficient Neighborhood-Based Topic Modeling for Collaborative Audio Enhancement on Massive Crowdsourced Recordings,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Shanghai, China, March 20-25, 2016. [pdf][↩]