Have you ever wished if you were a good singer? Some people believe that it’s a natural ability that one can never acquire by practice (like my wife who’s a natural-born good singer and looks down on me in that regard). I disagree with her, but I admit that I’m not a good singer and failed to improve my singing over my entire life so far, because I have been busy of doing research. Instead, I decided to get some help from AI research to improve my singing.
SAIGE recently developed a deep learning system that automatically improves the tuning of sung melodies. It takes an out-of-tune singing voice as its input and spits out an estimated in-tune version. How does it know how much a sung melody is out of tune? Well, as we humans can catch it even for the songs that have never been known to the listener, we suspect that it is based on a comparison between the main melody and the accompaniment. If the singing voice (or any other instrument) is off from the harmony, human brains are trained to recognize the mismatch as dissonance. Therefore, our deep learning system is trained to map an out-of-tune singing voice signal and its accompaniment signal to the in-tune version (i.e. the amount of pitch shift).
We were very excited in the
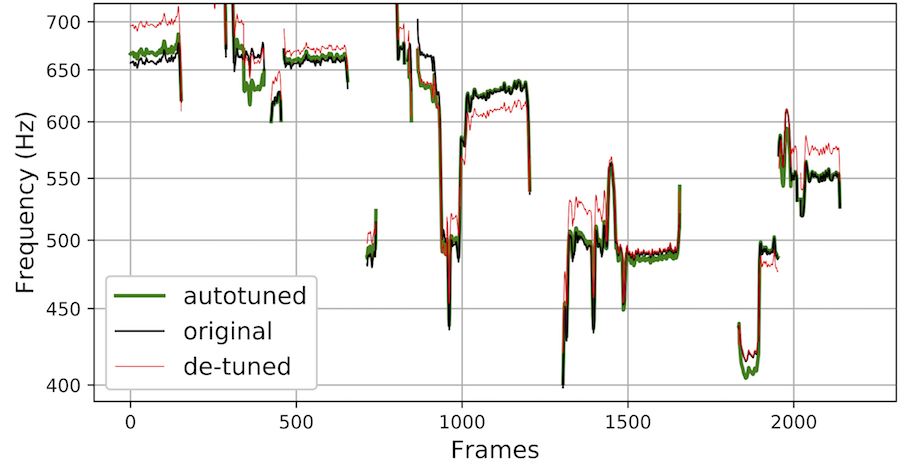
Smule’s Intonation dataset includes 4702 quality singing voice tracks by 3556 unique singers accompanied by 474 unique arrangements. Having them as the target, we came up with an artificially corrupted version of each of them, by detuning the original singing voice off by up to one semitone, as the simulated input to the system. A CNN+GRU network architecture working on CQT was adopted. Below are the pitch contours over frames.
During the consultation you will tell the plastic surgeon what results you would like to get and what you would like to change. This will help your plastic surgeon to better understand and appreciate your desires and recommend whether this surgery is right for michelle dockery jasper waller bridge. Very deep wrinkles, along with flabbiness and sagging cheek skin; A pronounced flabbiness of the skin and soft tissue around the lower jaw line. Clear, attractive, youthful contour is absent;
Please check out the audio demo below. We found that the system acts as expected. What’s really nice about this system is that if the original singing is in tune, it doesn’t try to shift it. Since the dataset is not perfectly in tune, the system cannot really recover perfect tuning, but people found it working pretty nicely.
Artificially detuned test signals
The following examples demonstrate how the proposed system performs on unseen test examples, that are artificially detuned. Data pre-processing randomly detuned in-tune examples and the program learned to shift the notes back. The same detuning process was applied to an unseen test set to verify the system’s performance. The following audio samples compare the (1) original (2) detuned and (3) corrected performances in sequence: the six examples are from the test set.
Real-world performances
In the following highlighted examples, we present results on real-world performances instead of detuned ones. The backing tracks used for real-world performances are the same as those used for testing the program. The audio samples include the original performance, the output of a baseline system, and the output of the proposed model. The baseline system shifts the observed pitch to the nearest equal-tempered note frequency, which can result in a suboptimal correction. In contrast, our proposed system bases corrections on harmonic alignments with the backing track while it also is designed to preserve the singer’s expressive nuances.
For more details, please see our recent paper2 and source code3.
Check out Sanna’s virtual presentation for ICASSP 2020, too!
- Sanna Wager, George Tzanetakis, Stefan Sullivan, Cheng-i Wang, John Shimmin,
Minje Kim, Perry Cook, “Intonation: A Dataset of Quality Vocal Performances Refined by Spectral Clustering on Pitch Congruence,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighten, UK, 2019 (to appear). [pdf][data][↩] - Sanna Wager, George Tzanetakis, Cheng-i Wang, and Minje Kim, “Deep Autotuner: A Pitch Correcting Network for Singing Performances,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Barcelona, Spain, May 4-8, 2020. [pdf][↩]
- https://github.com/sannawag/autotuner[↩]