Scalability is a big deal when it comes to video coding. When you watch a movie via a streaming service on Friday night, the video quality fluctuates—it’s the video codec’s effort in providing the maximum video quality even though your internet connection suffers from intermittent congestion. It’s better than waiting for the buffering, isn’t it?

So, what does scalability mean in the context of source separation or speech enhancement (SE), especially when the system involves complex machine learning models? Imagine you are on the phone and the device does some active speech enhancement to improve the speech quality during the remote conversation. But your device might be doing something else in addition to that, such as a live stream of the video capture of the frontal camera. You know what? You are out of juice, too… What if the machine learning-based SE system is scalable so that it goes into some kind of battery-saving mode? Then, you may still enjoy a certain level of enhanced speech while you don’t have to worry about other applications and the battery.
A naïve approach would be to prepare a few different versions of the SE models from which the system selects the optimal one considering the tradeoff between the SE quality and model complexity.
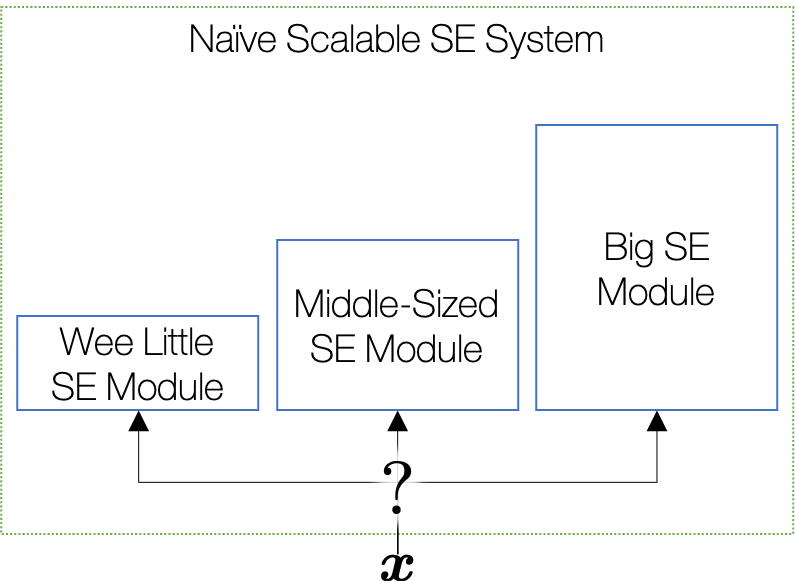
For example, if the system is with enough resources and nothing else is happening (i.e., no multitasking), the naïve scalable system may choose the big SE module, pursuing the best performance. On the contrary, the system will boil down to the smallest module when it decides to be conservative on resource usage.
Although this baseline system may provide the desired scalability, it is not the best use of memory space, as it has to retain all three different versions of the SE module. For simplicity, suppose that the three modules’ sizes are 1, 2, and 3M parameters. Then the total is 6M.
BLOOM-Net is our attempt to convert the popular masking-based source separation models into a scalable version. Compared to the naïve approach, our goal is to hack into the neural network architecture and modularize the topology. Now, we can do block-wise processing and adaptively change the number of participating blocks depending on the available system resource.
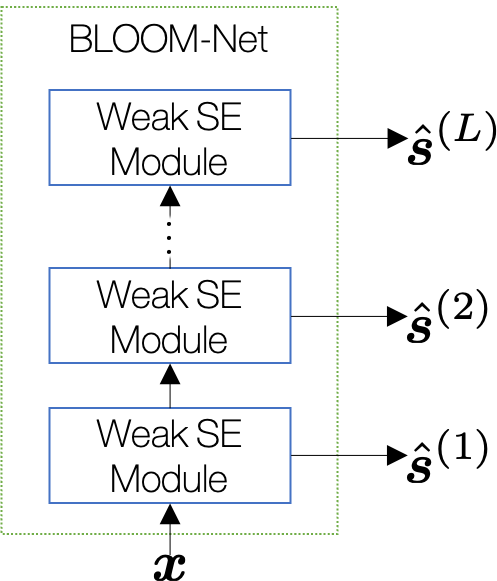
It works like this: if the system wants to go for the full-power mode, it uses all the stacked weak SE modules and produces  as the result. If
as the result. If  its performance should be as good as the “big” SE module shown in the naïve scalable baseline. With its least resource budget, BLOOM-Net will shrink and use only 1 block, whose output
its performance should be as good as the “big” SE module shown in the naïve scalable baseline. With its least resource budget, BLOOM-Net will shrink and use only 1 block, whose output  should be as good as the “wee little” module in the baseline.
should be as good as the “wee little” module in the baseline.
Size-wise, BLOOM-Net is clearly advantageous. If each weak SE module is with 1M parameters, then the total is  M, or 3M if there are such blocks. It’s a big saving if the system wants to prepare for various resource conditions, i.e., if is large.
M, or 3M if there are such blocks. It’s a big saving if the system wants to prepare for various resource conditions, i.e., if is large.
Hence, our first goal was to somehow disassemble the neural network model so that they operate in a block-wise manner. In addition, we also made sure that each intermediate result  is as good as the corresponding standalone SE module in the naïve baseline. To this end, we delved into the trending masking-based source separation models (Conv-TasNet1, DPRNN2, SepFormer3, and so on) and redesigned their “separator” part into a scalable version.
is as good as the corresponding standalone SE module in the naïve baseline. To this end, we delved into the trending masking-based source separation models (Conv-TasNet1, DPRNN2, SepFormer3, and so on) and redesigned their “separator” part into a scalable version.
For those who need more details, more specifically, the separator part now works as a series of blocks, each of which tries to improve the residual of the previous block. Since this serialization of “residual learning” is happening in the feature space, we can expect better performance and more compact architecture. It’s actually a little more complex than this simplified explanation, so we encourage the readers to check out our paper4 for more details. Anyhow, the actual block diagram looks like this:

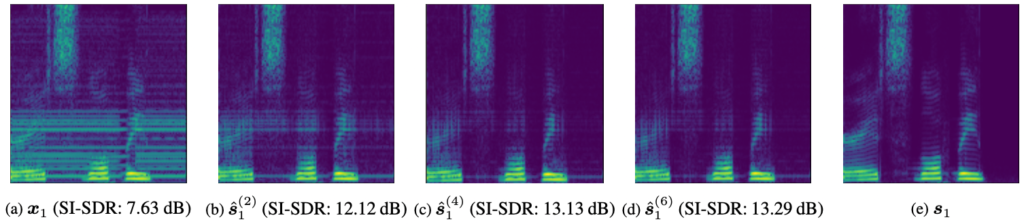
The system indeed acts as expected (shown in the following figure). If it chooses only a couple blocks ( ), the SE performance is only acceptable but it’s budget-friendly. And it can reach the best performance when (
), the SE performance is only acceptable but it’s budget-friendly. And it can reach the best performance when ( ).
).
To summarize, we claim that these are the main contribution of BLOOM-Net:
- The redesigned masking-based SE model supports scalable rearrangement of the participating blocks
- They are compact in terms of spatial complexity
- For any choice of the model gives the best possible SE result, comparable to the same-sized state-of-the-art
p.s. The abbreviated name BLOOM-Net is dedicated to our hometown, Bloomington, IN.
Paper
Please check out our paper for more details:
Sunwoo Kim and Minje Kim, “BLOOM-Net: Blockwise Optimization for Masking Networks Toward Scalable and Efficient Speech Enhancement,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, May 22-27, 2022 [pdf].
Source Codes
We also open-sourced the project here: https://github.com/kimsunwiub/BLOOM-Net
ICASSP 2022 Virtual Presentation
This material is based upon work supported by the National Science Foundation under Grant Numbers 1909509 and 2046963. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
- Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019.[↩]
- Y. Luo, Z. Chen, and T. Yoshioka, “Dual-path RNN: effi- cient long sequence modeling for time-domain single-channel speech separation,” in Proc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2020.[↩]
- C.Subakan,M.Ravanelli,S.Cornell,M.Bronzi, andJ.Zhong, “Attention is all you need in speech separation,” in Proc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2021, pp. 21–25.[↩]
- Sunwoo Kim and Minje Kim, “BLOOM-Net: Blockwise Optimization for Masking Networks Toward Scalable and Efficient Speech Enhancement,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, May 22-27, 2022 [pdf].[↩]