As we’ve proposed in the BLOOM-Net project, scalability matters. Just to reiterate the argument here once again, the main issue with the current deep learning-based models for speech enhancement is that they tend to be trained for just one particular goal: best-effort enhancement. The model architecture is fixed from the get-go and is trained to estimate the clean speech target no matter what. With BLOOM-Net, we showed that it’s possible to come up with a flexible model architecture that scales up and down freely, depending on the system’s resource budget. For example, if the system lacks computational power (e.g., a phone running out of battery), the model can shrink to its minimal version, i.e., battery saving mode, which is still trained to produce an acceptable enhancement result. We actually see many such scalable systems in other applications, e.g., the video codec that lowers its bitrate when the network bandwidth is not good enough, a cordless vacuum that lowers its RPM when the floor is already clean enough, etc.
In this scalable and efficient speech enhancement (SESE) project, I delved into the concept of scalability from the perspective of the recently proposed concept of cold diffusion1. Cold diffusion was originally proposed as a generative model that works with deterministic noise input, and it was later applied to speech enhancement, showing promising results2 due to its convenient flexibility that it accepts any type of noise as input, i.e., the noisy speech. Although we relate the proposed method to cold diffusion’s sampling process, we would like to note that the proposed method presents a totally different sampling process, which we argue is more efficient and convenient to interpret than cold diffusion.
One-shot speech enhancement (SE)

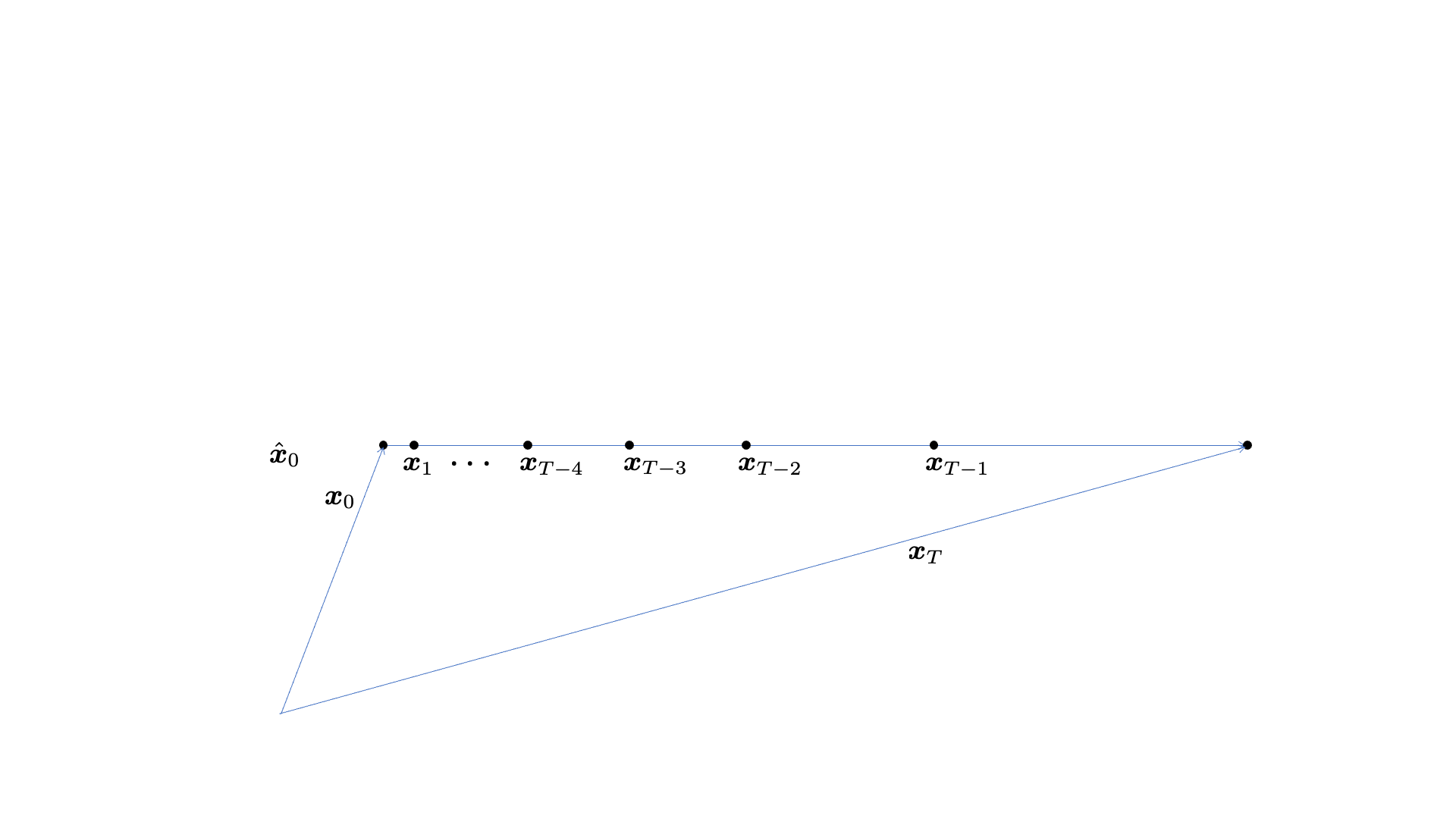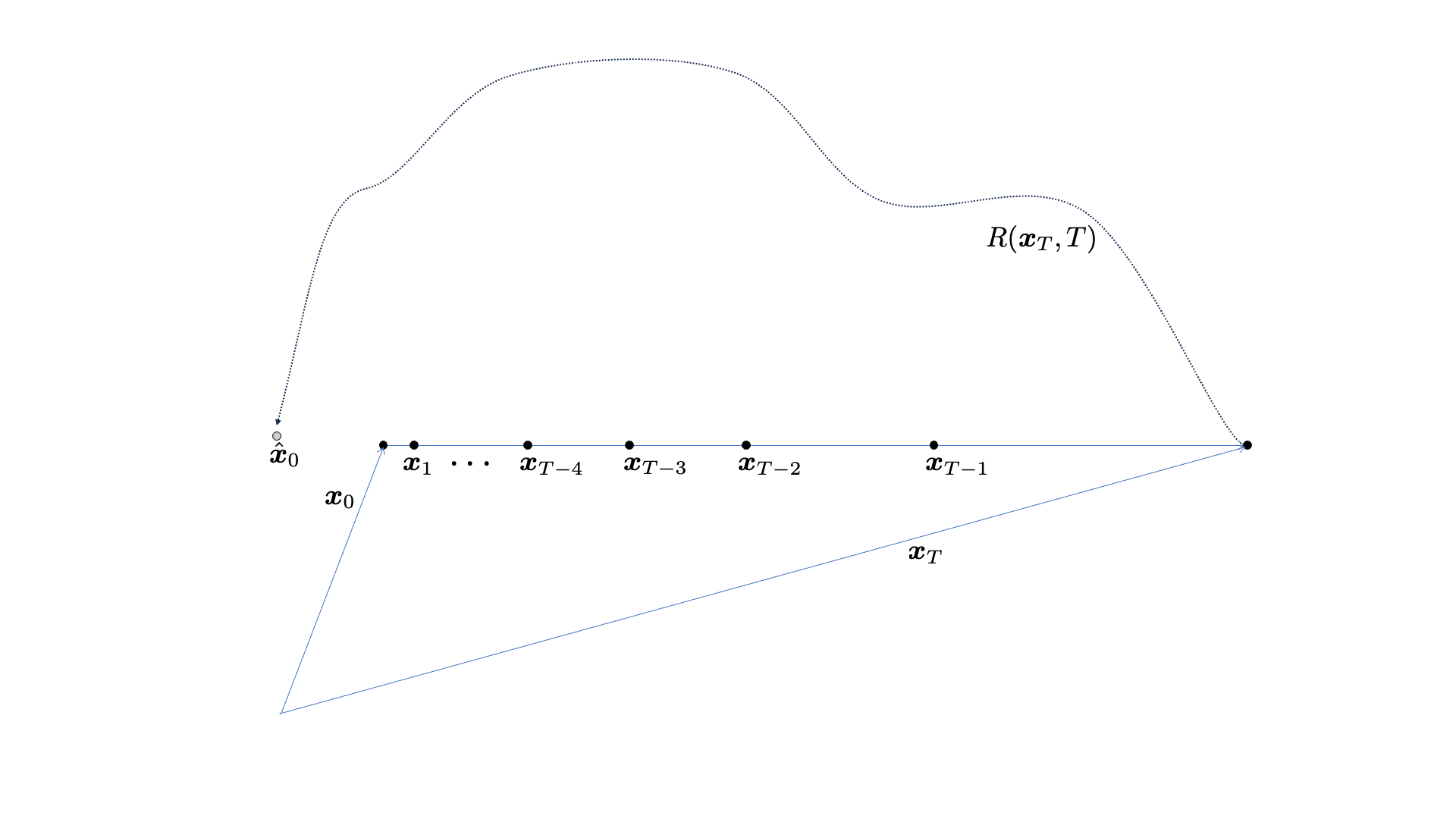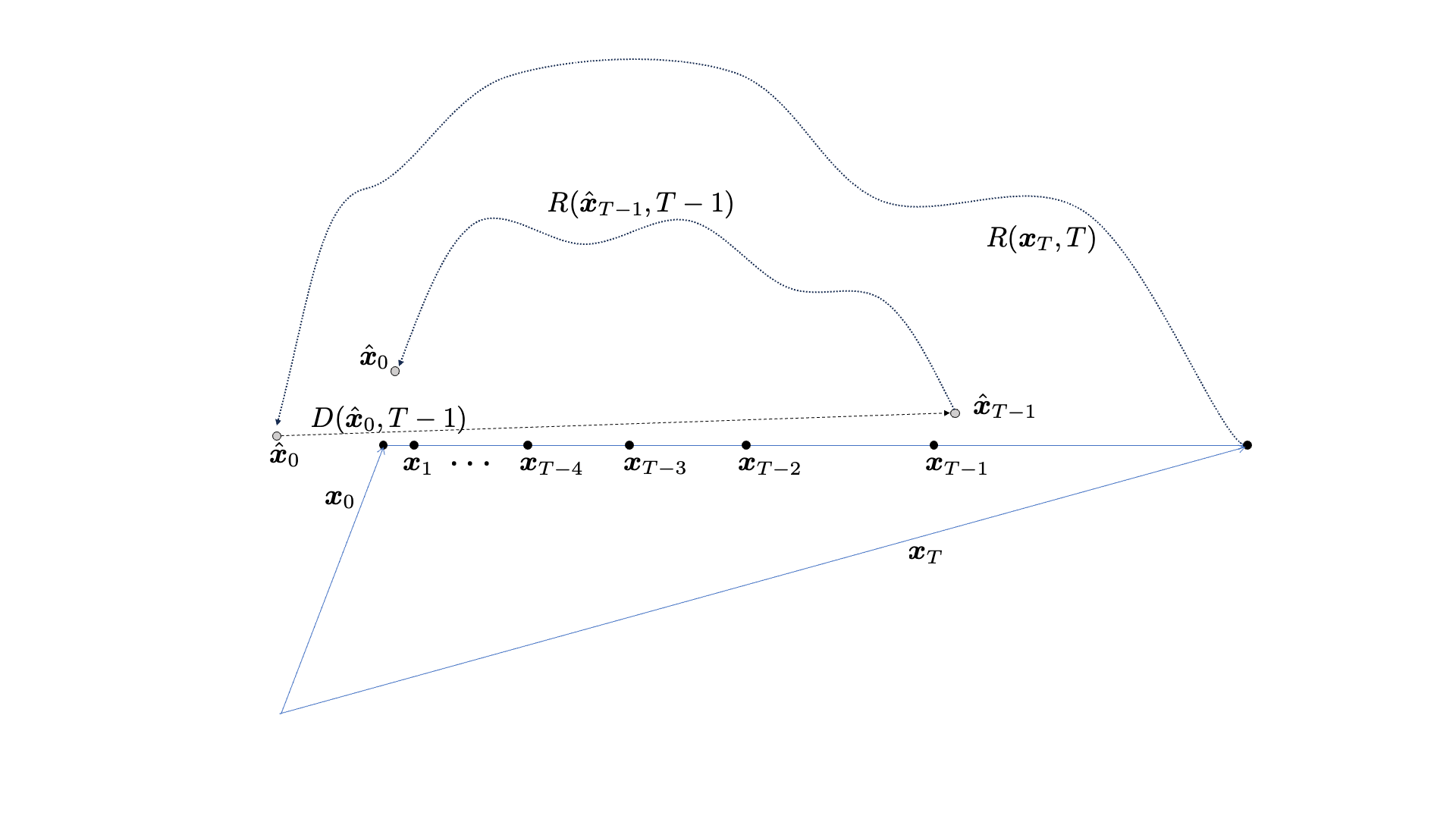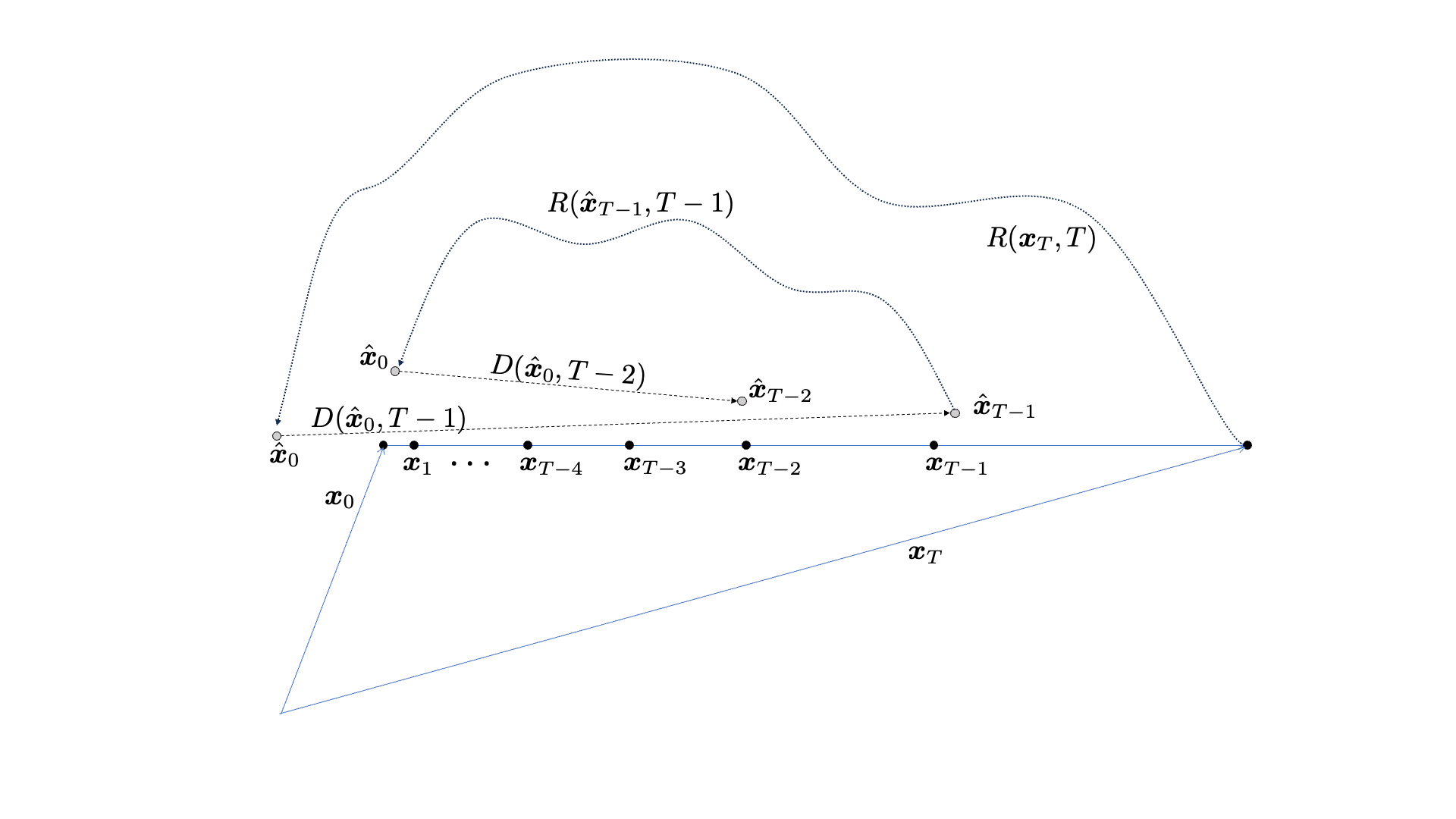
Let’s begin with the traditional SE system. In the simplest denoising case, suppose that the clean speech signal  is contaminated by a noise source
is contaminated by a noise source  , which forms the noisy speech utterance
, which forms the noisy speech utterance  (see the figure above where these variables are represented in a vector space). Given the noisy utterance, which is the only information available during the test time, the SE model’s job is to recover the clean speech , i.e., the estimate
(see the figure above where these variables are represented in a vector space). Given the noisy utterance, which is the only information available during the test time, the SE model’s job is to recover the clean speech , i.e., the estimate  is trained to be as similar as possible to . Of course, a very capable model can be defined with a large architecture that performs this nonlinear mapping pretty successfully. At the same time, for a resource-constrained environment, a small model is tasked to do its best. We denote these SE models by
is trained to be as similar as possible to . Of course, a very capable model can be defined with a large architecture that performs this nonlinear mapping pretty successfully. At the same time, for a resource-constrained environment, a small model is tasked to do its best. We denote these SE models by  . In the figure above, for example, two
. In the figure above, for example, two  cases are shown to represent the typical relationship between the model complexity and its performance.
cases are shown to represent the typical relationship between the model complexity and its performance.
We call this traditional SE method “one-shot” SE, because it does not involve any iterative process for its inference. Just a one-time inference routine of the neural network will produce an enhanced result. From the scalability perspective, the system has to maintain two different versions of the models that are selectively used depending on the resource constraint. In addition, there is a chance that the estimate  can be farther away from the original speech
can be farther away from the original speech  , if the small model is not capable of learning the complex mapping between and .
, if the small model is not capable of learning the complex mapping between and .
Cold Diffusion for SE
The cold diffusion method for SE does this job in an iterative fashion. It starts from the noisy utterance as the “noise” input to the reverse diffusion process. Since the reverse diffusion process consists of multiple sampling steps, we introduce the step-index  with
with  and
and  being the target clean speech (i.e., ) and input noisy speech (i.e.,
being the target clean speech (i.e., ) and input noisy speech (i.e.,  ), respectively. It assumes that the intermediate sample
), respectively. It assumes that the intermediate sample  is a linear combination of and . For example, there is a degradation process that contaminates the clean speech into any intermediate version , i.e.,
is a linear combination of and . For example, there is a degradation process that contaminates the clean speech into any intermediate version , i.e.,  . The degradation function is controlled by the sampling step index , which also defines the amount of degradation for the linear combination.
. The degradation function is controlled by the sampling step index , which also defines the amount of degradation for the linear combination.
Then, the SE model performs the best-effort SE given any intermediate input . In the cold diffusion context, we call this the restoration function. The process begins with the initial input , whose enhancement result  is fed back to the degradation function to estimate the next intermediate sample
is fed back to the degradation function to estimate the next intermediate sample  —it’s only an estimate as the system doesn’t have access to clean speech , so instead, the degradation function has to use the estimated one, . The sampling process repeats this cycle until it reaches
—it’s only an estimate as the system doesn’t have access to clean speech , so instead, the degradation function has to use the estimated one, . The sampling process repeats this cycle until it reaches  , which will be used as the final input to the restoration function
, which will be used as the final input to the restoration function  .
.
The cold diffusion for SE paper2 has it’s own unfolding mechanism that prevents the propagation of reconstruction error, so it’s a little more complicated than the figure.
The main issues with this cold diffusion process are
- The restoration function
 is a generic one that needs to handle any intermediate input signals for all . To this end, the model takes as a conditioning input. While it’s a valid way to inform the model of the amount of denoising to be done, the model becomes larger to generalize well to all those use cases.
is a generic one that needs to handle any intermediate input signals for all . To this end, the model takes as a conditioning input. While it’s a valid way to inform the model of the amount of denoising to be done, the model becomes larger to generalize well to all those use cases. - The restoration function always conducts the best-effort enhancement. In some applications, though, it might be too challenging of a target to achieve.
In other words, in cold diffusion, the sampling process always goes back to the clean target no matter where degradation step the sampling process is positioned. Given that it has to come back to the intermediate mixtures anyway via the degradation process, is there any better way to do this iterative restoration? What if the intermediate restoration step conducts a compromised, thus easier target?
The proposed SESE method
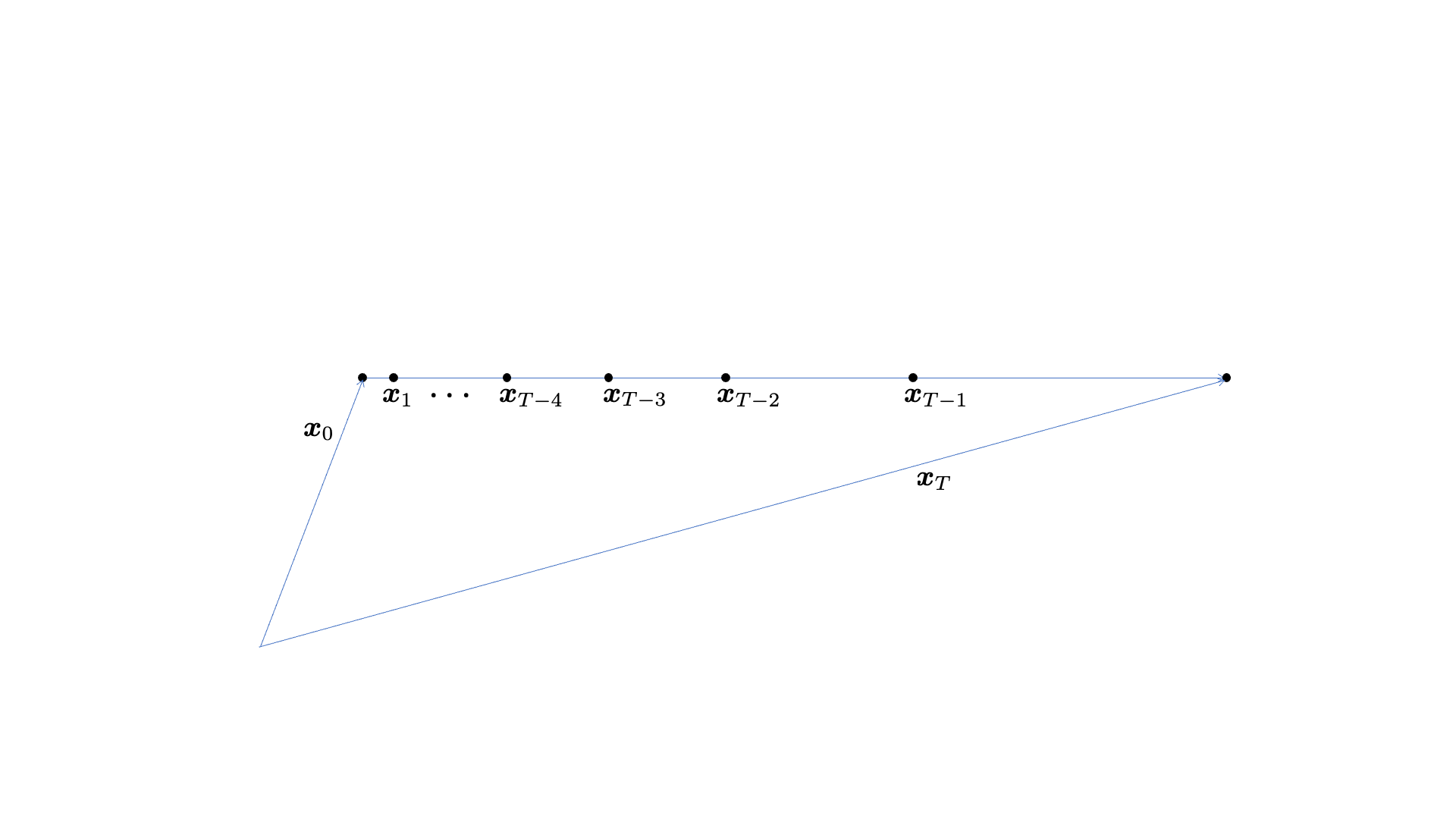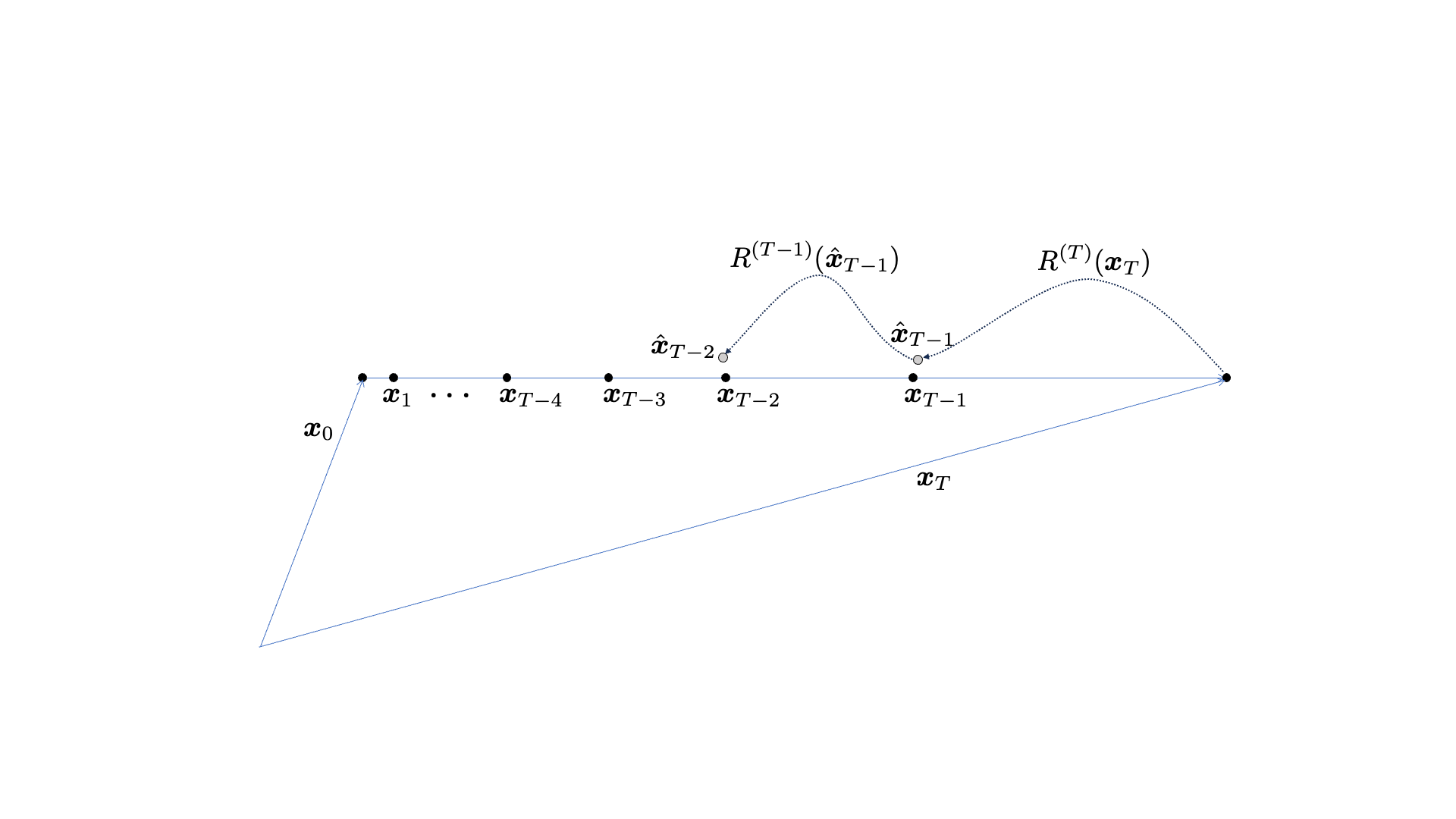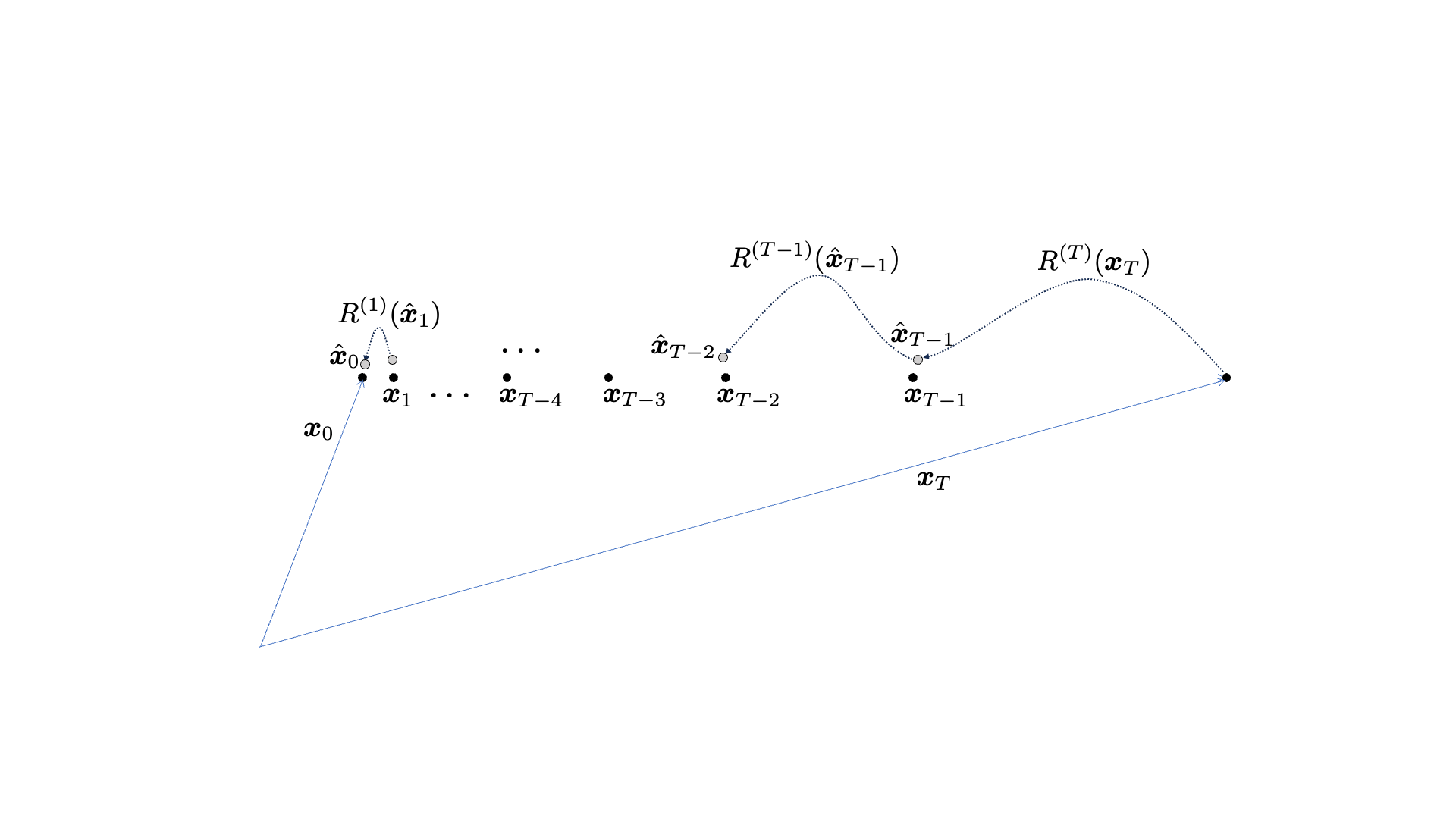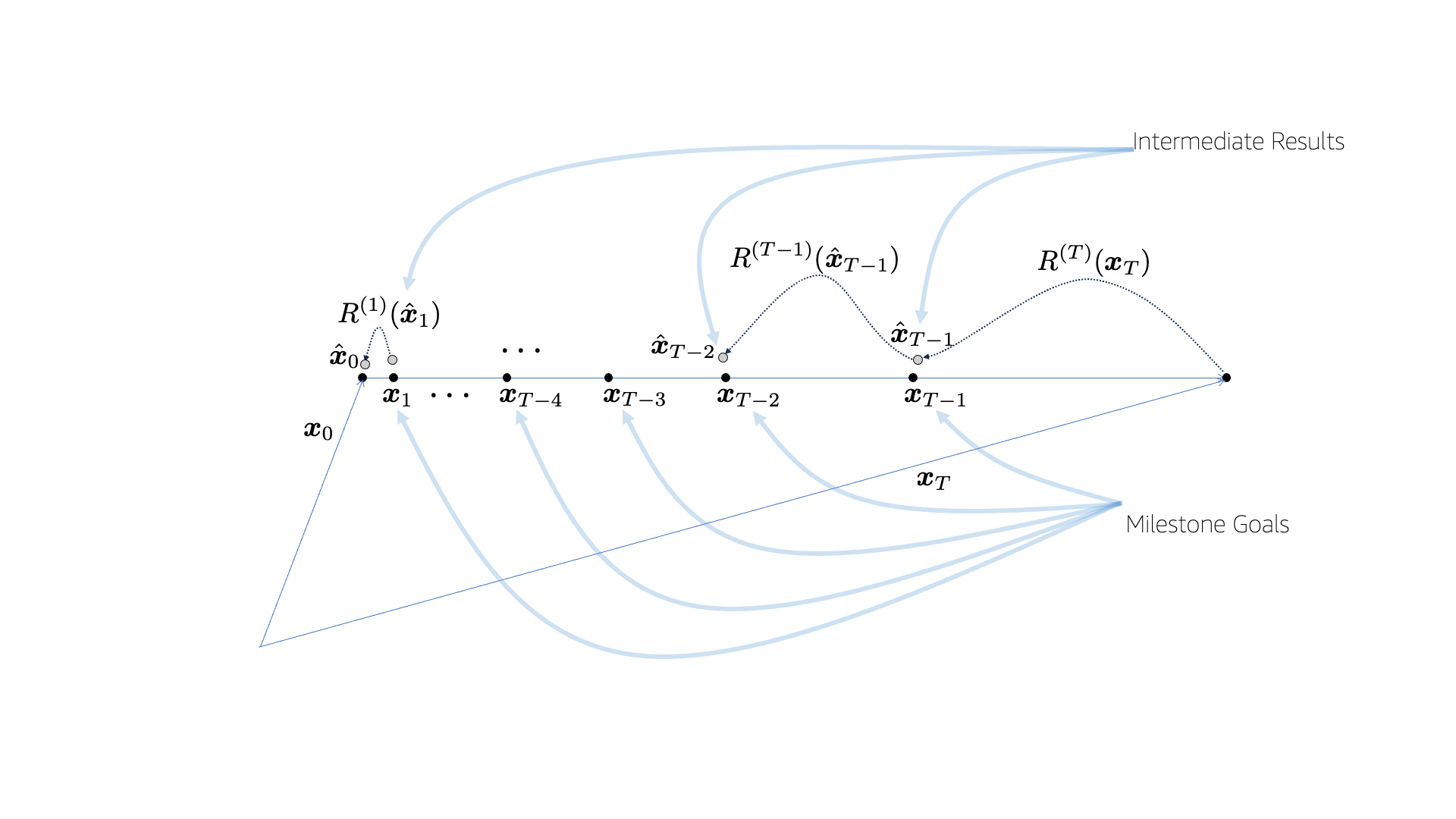
The proposed SESE method employs multiple restoration functions  each of which is responsible for the particular step’s denoising. So, eventually, the proposed SESE method drifted away from the original cold diffusion algorithm. These step-by-step restoration functions have some advantages.
each of which is responsible for the particular step’s denoising. So, eventually, the proposed SESE method drifted away from the original cold diffusion algorithm. These step-by-step restoration functions have some advantages.
- Each restoration task learns a subtle change between
 and
and  . Since the input and target of mapping are on the smooth interpolation line, their difference is easier for the model to learn, leading to better approximation. We call these intermediate mixtures milestone goals.
. Since the input and target of mapping are on the smooth interpolation line, their difference is easier for the model to learn, leading to better approximation. We call these intermediate mixtures milestone goals. - The process can be redefined to learn the residual between the target and the input, i.e.,
 , rather than the output directly. A well-known benefit introduced in the ResNet architecture. We cold this variation ResSESE.
, rather than the output directly. A well-known benefit introduced in the ResNet architecture. We cold this variation ResSESE. - Small neural network architectures are good enough to learn these mapping functions (0.58% of the cold diffusion model used for SE!).
- The intermediate results are useful. These intermediate results are with less artifact, although they still contain the original noise source, which is louder when is large, while it can be suppressed further as nears 0.
- The model is scalable as the intermediate solutions are cheaper to produce.
- We found that SESE requires fewer sampling steps.
 or
or  gave good results.
gave good results. - From the learning perspective, this process can be seen as guided learning as the intermediate solutions are compared with the milestone goals multiple times, eventually leading to better performance.
For more information, please take a look at the paper.
Paper
Minje Kim and Trausti Kristjansson, “Scalable and Efficient Speech Enhancement Using Modified Cold Diffusion: a Residual Learning Approach,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Seoul, Korea, Apr. 14-19, 2024 [pdf]
Sound Examples
In the following examples, you will see three ResSESE results near the end of the process, e.g.,  , when the total number of sampling steps is . Here, to help you understand the intermediate nature of the input, I made up a concept called signal-to-mixture (SMR) ratio, which is -INF if the input is the pure mixture
, when the total number of sampling steps is . Here, to help you understand the intermediate nature of the input, I made up a concept called signal-to-mixture (SMR) ratio, which is -INF if the input is the pure mixture  and goes up as the clean speech is mixed up more as reaches
and goes up as the clean speech is mixed up more as reaches  . These SMR values are the input’s noisiness at the given step and the sound example is shown as a result of that step’s processing by
. These SMR values are the input’s noisiness at the given step and the sound example is shown as a result of that step’s processing by  . For example, one of the presented examples
. For example, one of the presented examples  is step
is step  ‘s result via
‘s result via  , where
, where  ‘s SMR is -6.1 dB, meaning that was mixed in a lot more than
‘s SMR is -6.1 dB, meaning that was mixed in a lot more than  in
in  .
.
Sound Examples #1
Sound Examples #2
More “final” examples can be found below. Here,  stands for the total number of steps during the diffusion process, while
stands for the total number of steps during the diffusion process, while  is the index within the process, i.e., when
is the index within the process, i.e., when  , the inverse diffusion process is finished.
, the inverse diffusion process is finished.
Sound Examples #3
 )
) ))
))Sound Examples #4
)))Sound Examples #5
)))Sound Examples #6
)))Acknolwedgement
This work was done during my time at Amazon Lab126.
- Arpit Bansal, Eitan Borgnia, Hong-Min Chu, Jie S. Li, Hamid Kazemi, Furong Huang, Micah Goldblum, Jonas Geiping, Tom Goldstein, “Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise,” arXiv:2208.09392, 2022.[↩]
- Hao Yen, François G. Germain, Gordon Wichern, Jonathan Le Roux, “Cold Diffusion for Speech Enhancement,” IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2023.[↩][↩]