Have you ever wondered about a speech codec that’s dedicated to your speech trait? Why? Of course, it is to reduce the bitrate while maintaining the speech quality after decoding—the codec knows a lot about your voice, while it doesn’t have to worry about compressing other people’s voices, it could achieve a better coding gain. Meanwhile, when it comes to neuralspeech codecs, it might also be possible to reduce the model architecture. A relatively smaller model architecture might be just fine to achieve the same coding gain, because we don’t expect the codec to generalize to all sorts of speech variations spoken by many people.
It’s actually not a well-defined problem, as there are just so many different ways to define one’s voice. So, it’s not clear to develop a traditional codec in this way. Our goal in this project is to leverage some machine learning principles to achieve the personalization goal in neural speech coding.
The Overview of the System
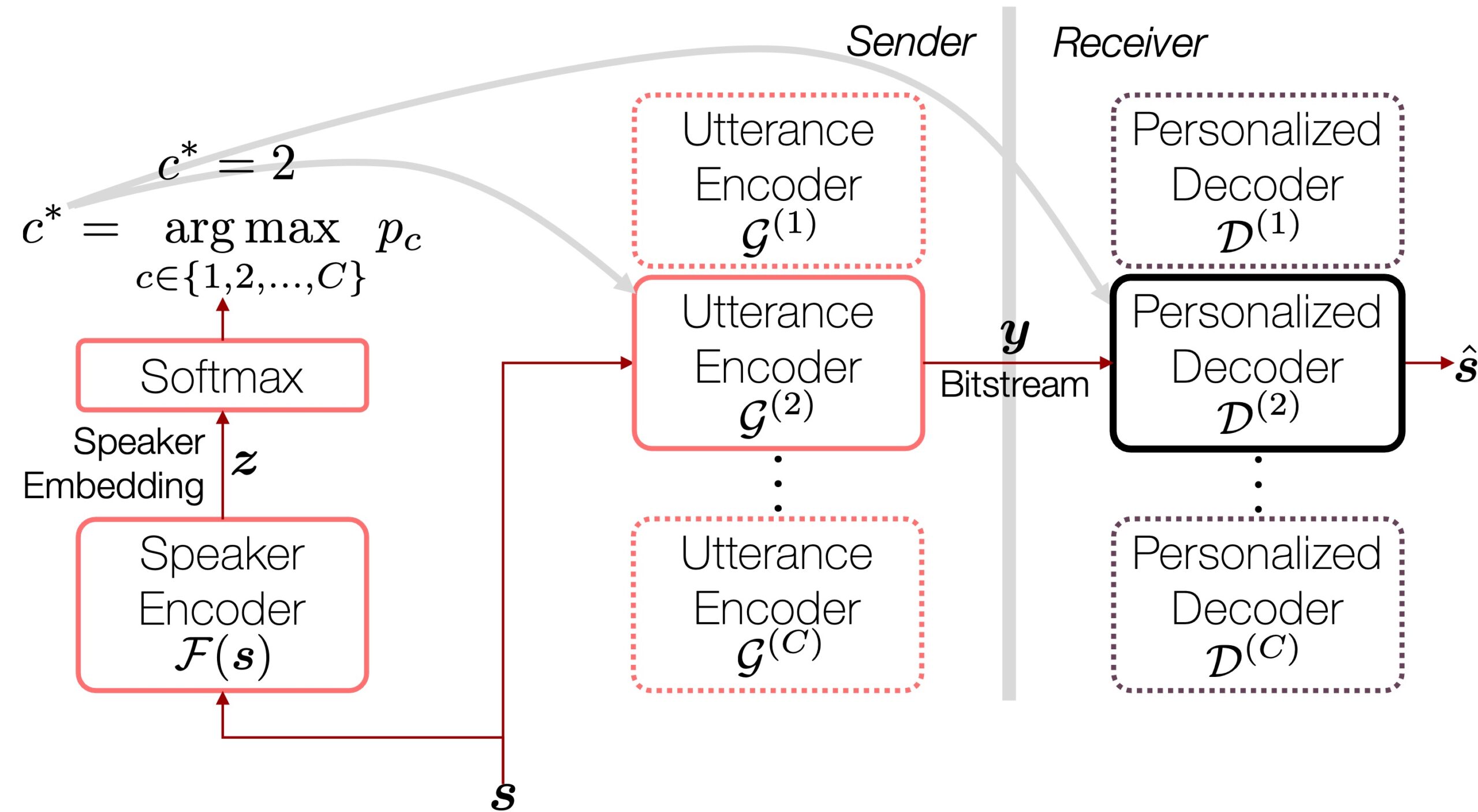
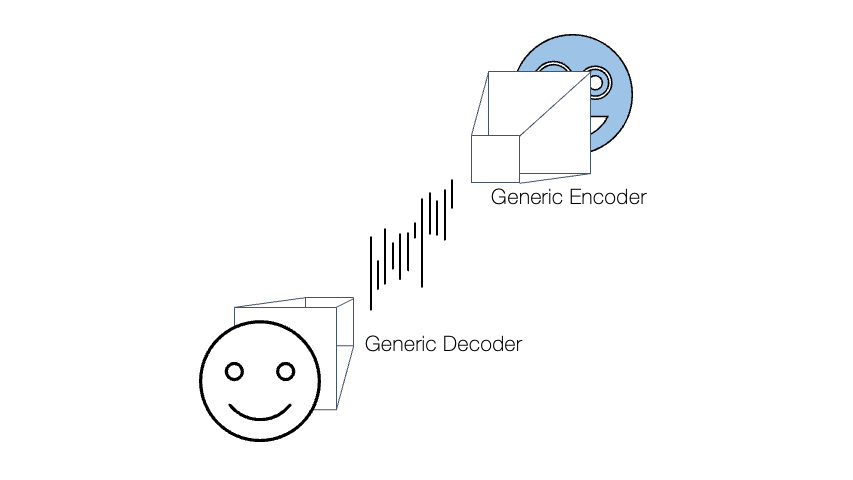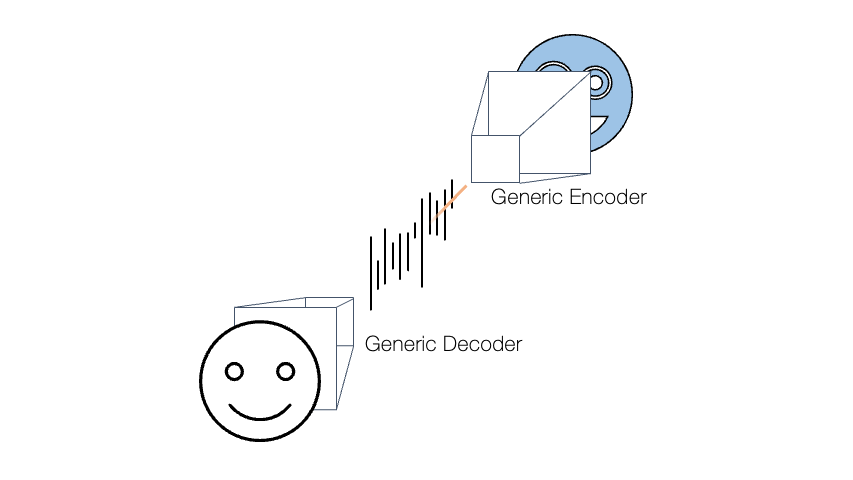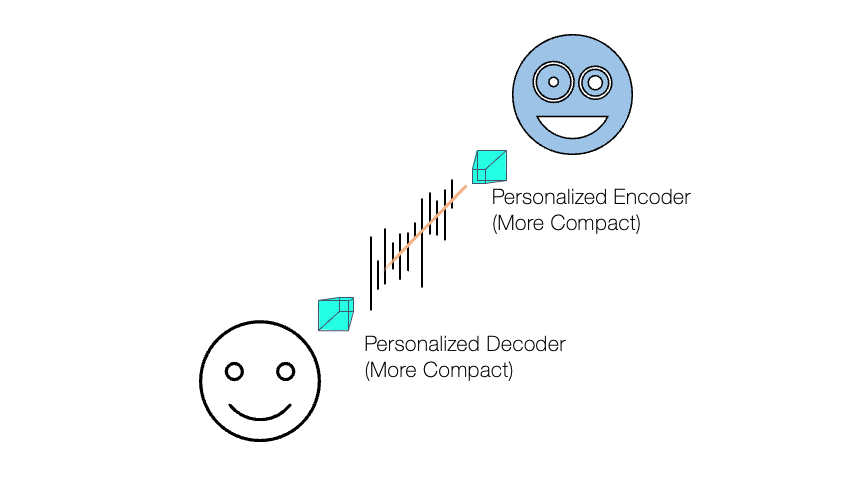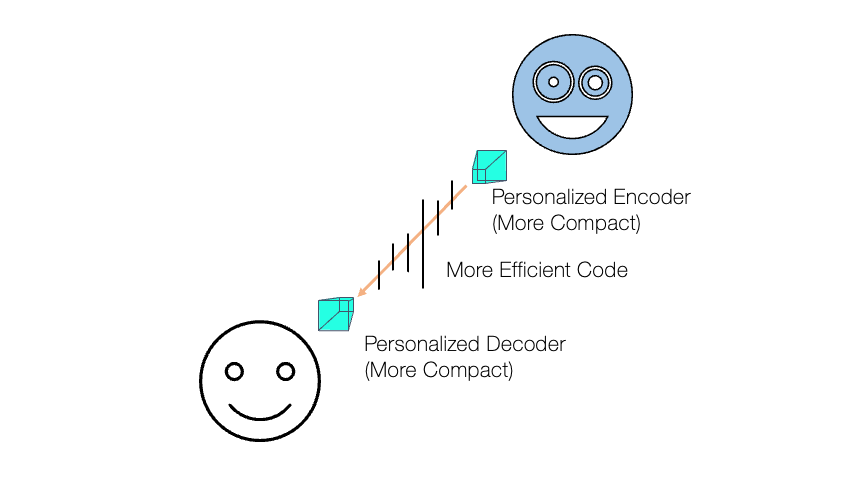
We assume that all human speakers can be grouped into  exclusive subsets, each containing speakers who sound similar to each other. It’s our compromise, because, otherwise, we need to handle too many specific cases for everyone. Hence, what we actually develop is not a personalized codec, but a codec that works well for a certain group of people who share similar speech characteristics.
exclusive subsets, each containing speakers who sound similar to each other. It’s our compromise, because, otherwise, we need to handle too many specific cases for everyone. Hence, what we actually develop is not a personalized codec, but a codec that works well for a certain group of people who share similar speech characteristics.
Then, during the test time, for a given utterance  , our system first decides which speaker group the utterance belongs to. For example, a simple classifier can do this job (e.g., a softmax layer applied to the speaker embedding). Based on the classification, the system can choose the most suitable encoder, because we prepared group-specific encoders ahead of time, hoping that each of them is doing the best speech compression for the corresponding speaker group. In the figure, for example,
, our system first decides which speaker group the utterance belongs to. For example, a simple classifier can do this job (e.g., a softmax layer applied to the speaker embedding). Based on the classification, the system can choose the most suitable encoder, because we prepared group-specific encoders ahead of time, hoping that each of them is doing the best speech compression for the corresponding speaker group. In the figure, for example,  is chosen as it gives the highest softmax probability. This process ensures that the bitstream
is chosen as it gives the highest softmax probability. This process ensures that the bitstream  contains the test speaker’s personality even at a very low bitrate thanks to the adequate choice of the encoder
contains the test speaker’s personality even at a very low bitrate thanks to the adequate choice of the encoder  .
.
On the receiver side, the system has to know which decoder module to choose from, because, once again, we prepared group-specific decoders as well. To this end, along with the code , the decoder also needs to know the index information, i.e., , the most suitable group the sender’s voice belongs to.
During training, we use the estimated speaker group indices instead of the ground truth, so the codec is robust to the misclassification error.
How Do We Define the Speaker Groups?
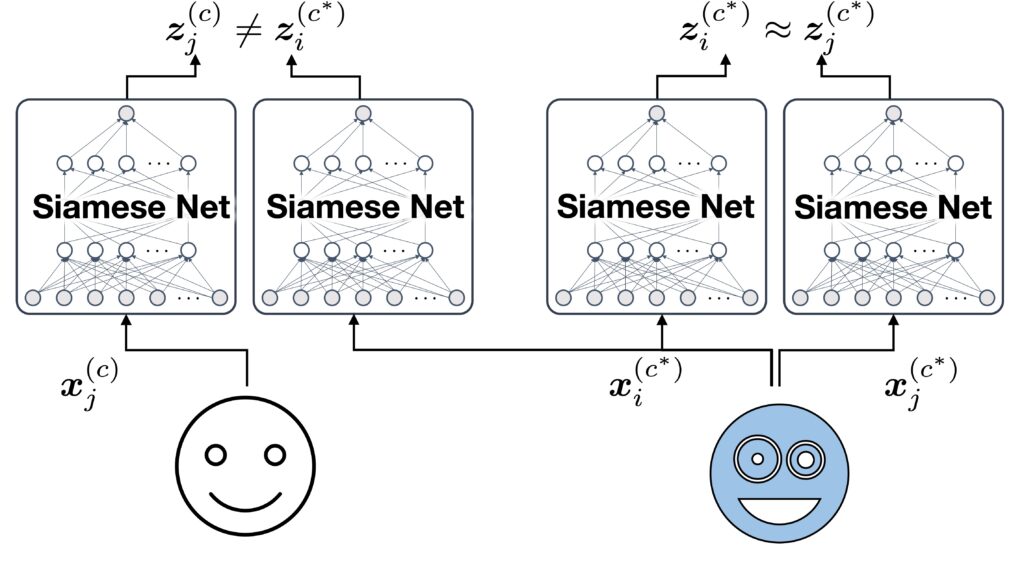
Following the previous work1, we first learn a speaker embedding space via contrastive learning and then perform k-means clustering in there. To this end, we use a Siamese network that is trained to learn embedding vectors  and
and  that are trained to be similar if the utterances were spoken by the same person, i.e.,
that are trained to be similar if the utterances were spoken by the same person, i.e.,  , and vice versa, i.e.,
, and vice versa, i.e.,  .
.
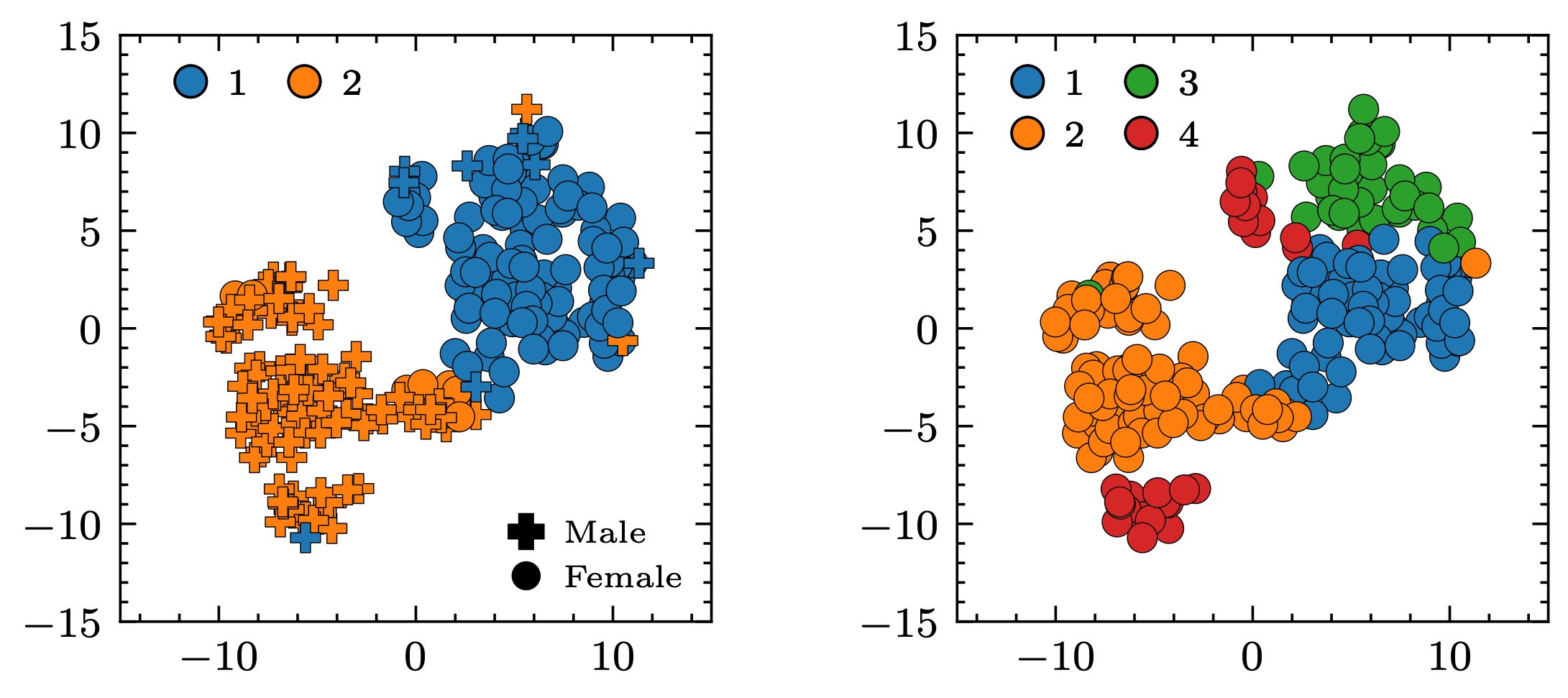
Since these  vectors are learned to be similar in terms of a linear relationship, e.g., inner product, a k-means clustering in the space works fine. Below is a result when
vectors are learned to be similar in terms of a linear relationship, e.g., inner product, a k-means clustering in the space works fine. Below is a result when  and
and  . The case “looks” weird as the red dots are spread into two places, but it might be just because of the heavy dimension reduction that happened for visualization in the 2d space. Interestingly, the case somehow corresponds to the speakers’ gender distribution.
. The case “looks” weird as the red dots are spread into two places, but it might be just because of the heavy dimension reduction that happened for visualization in the 2d space. Interestingly, the case somehow corresponds to the speakers’ gender distribution.
Personalized LPCNet
Since we are hardcore, we opted to use an already efficient codec based on LPCNet2 as our baseline. LPCNet is specially designed to meet the real-time communication requirement, so its architecture is already very compact even though the bitrate is very low. It means compressing LPCNet is challenging.
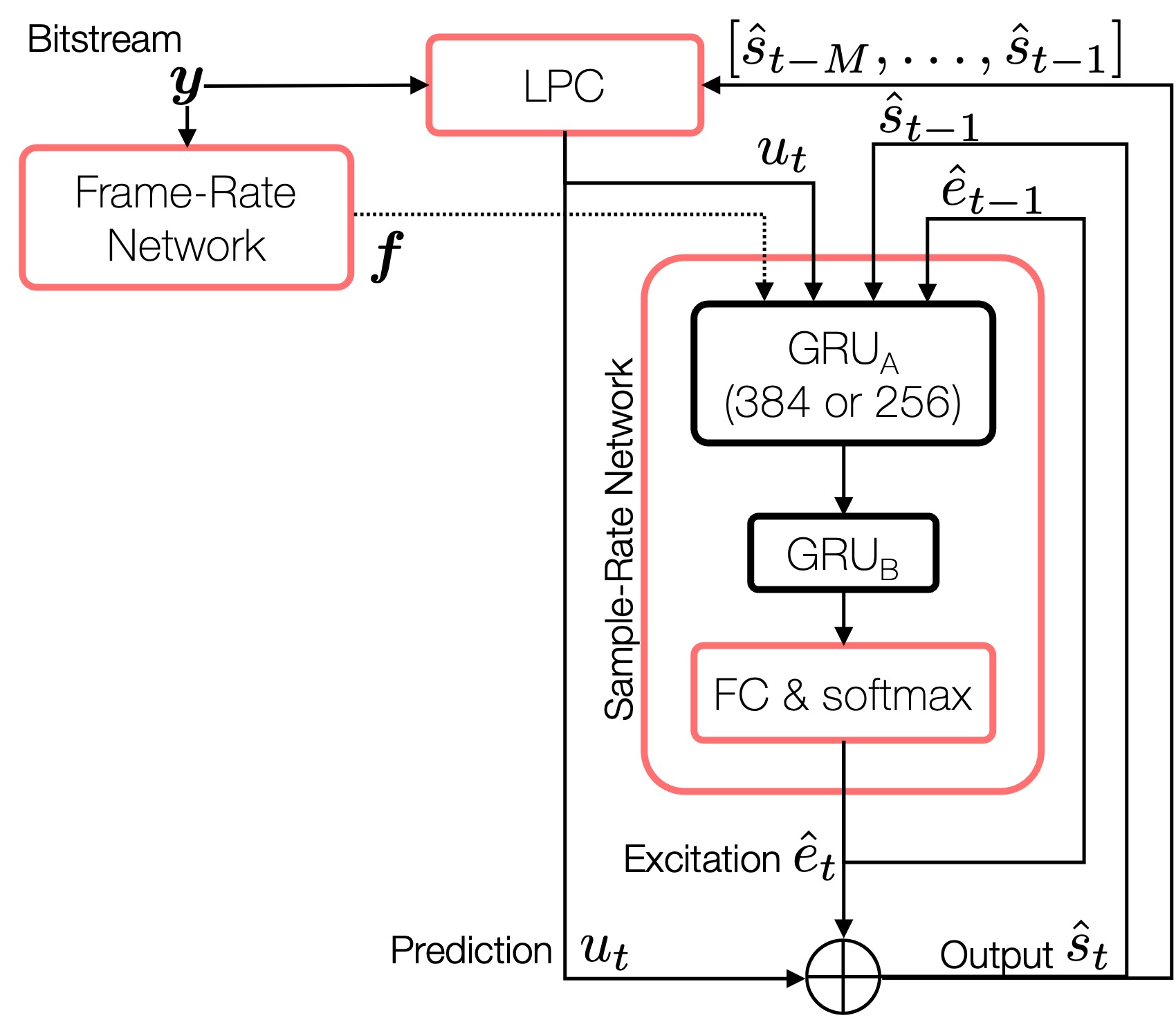
Since LPCNet doesn’t have a neural encoder (instead, it uses predefined codes based on cepstrum and pitch information), the personalized LPCNet only compresses its GRU-based decoder.
We evaluated two LPCNet systems with varying GRU layer sizes, ranging from 256 units to 384. Compared to the original setup with 384 units, the 256-unit GRU reduces the entire decoder’s complexity by about 36%. Below is the architecture, but it’s actually not very different from the original LPCNet’s, except for the first GRU layer, which changes its hidden unit numbers.
The Results
First, let’s see if the personalized model gives a lower validation loss.
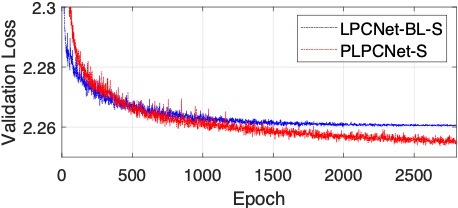
This means that the model’s objective performance is better than that of the regular LPCNet baseline.
But when it comes to speech/audio codecs, you don’t want to believe in the objective measurements too much. So, we conducted a MUSHRA-like test.
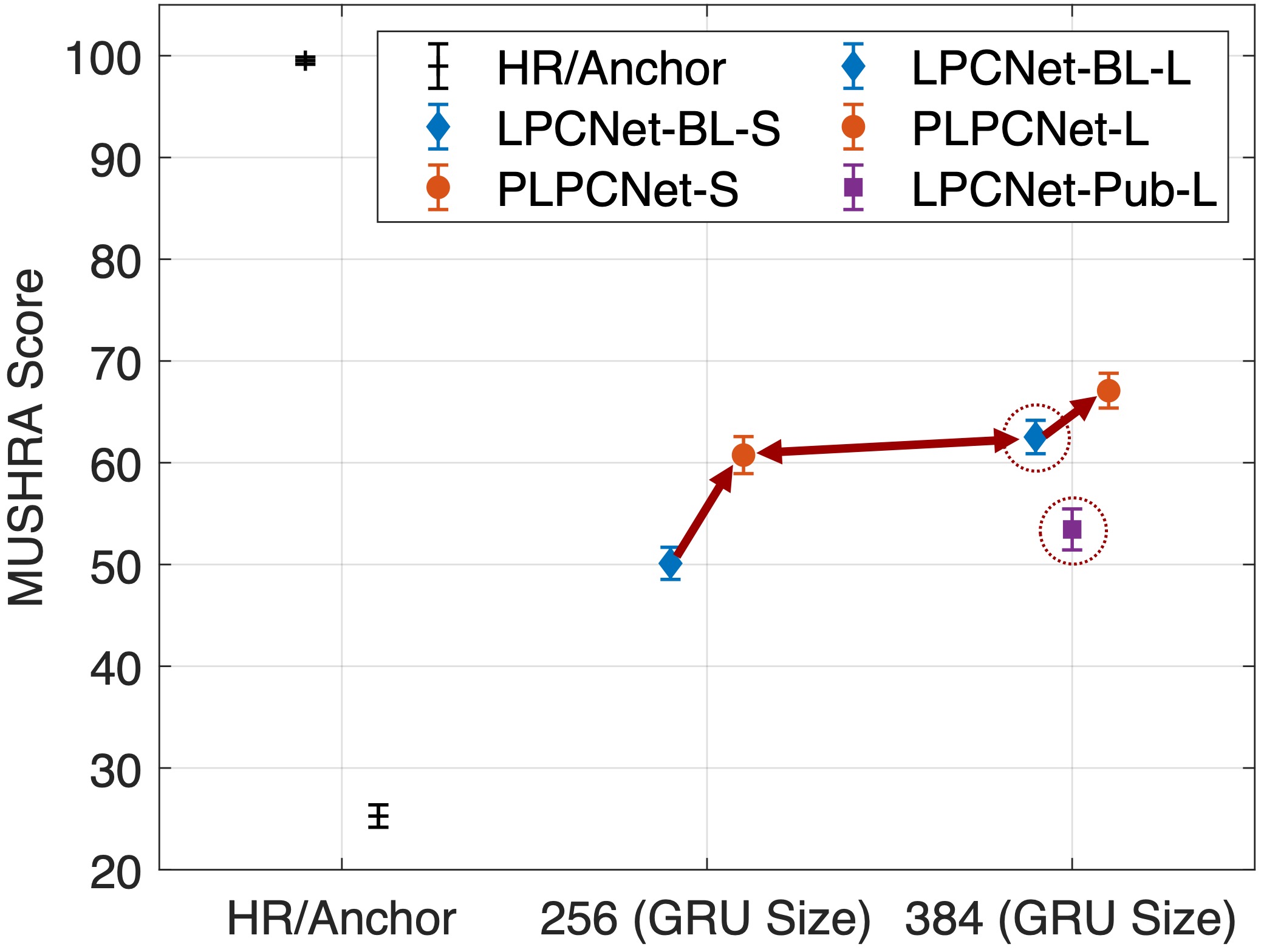
- (Look at the red dotted circles) First, we have to brag that we developed our own LPCNet baseline in Pytorch (the blue diamonds). If you compare the larger model’s performance to the original LPCNet implementation (purple square), you will see that ours is a little better. It might be because that our models have been trained and tested from the LibriSpeech corpus, requiring less generalization effort than the original LPCNer had to.
- (Look at the one-sided red arrows) Second, we can see that the personalized LPCNets (orange dots) improve their corresponding baseline LPCNet models (blue diamonds), if they are compared with the same-sized LPCNet baselines. This means the personalized model improves the codec’s sound quality at the same bitrate.
- (Look at the double-sided red arrow) If the small PLPCNet (256 GRU size) is compared with the large LPCNet (384 units), their confidence intervals overlap, meaning their performances are statistically on par. Hence, we can say that PLPCNet compresses the model by 36% without a loss of performance.
Sound Examples (1.6 kbps)
All the following examples are encoded with LPCNet’s default encoder at a bit rate of 1.6 kbps. Please use your headphones to check out the differences.
Example #1
Example #2
Example #3
Example #4
Paper
For more information, please read our ICASSP 2024 paper.
- Inseon Jang, Haici Yang, Wootaek Lim, Seungkwon Beack, and Minje Kim, “Personalized Neural Speech Codec,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Seoul, Korea, Apr. 14-19, 2024 [pdf].
※ This work was supported in part by Electronics and Telecommunica- tions Research Institute (ETRI) grant funded by the Korean government [23ZH1200: The research of the basic media contents technologies].
※ The material discussed here is partly based upon work supported by the National Science Foundation under Award #: 2046963, too. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
- Aswin Sivaraman and Minje Kim, “Zero-Shot Personalized Speech Enhancement Through Speaker-Informed Model Selection,” in Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, Oct. 17-20, 2021 [pdf, code, presentation video].[↩]
- Jean-Marc Valin, Jan Skoglund, “A Real-Time Wideband Neural Vocoder at 1.6 kb/s Using LPCNet,” Interspeech 2019 https://doi.org/10.48550/arXiv.1903.12087[↩]