TLDR: In this project, we developed an end-to-end neural network system that takes a music mixture as input and produces its remixed version per the user's intended volume changes of the component instruments. To the best of our knowledge, we propose the first end-to-end neural method that jointly learns music source separation and remixing together. We show our proposed neural remixing method is capable of a wider range of volume change compared to existing methods, ranging from −12 to 12 dB, and can deal with up to five sources.
For heavy music listeners, remixing is a common desire. If you want to practice a complex guitar solo, in addition to listening to that tricky part over and over again, you may want to boost the guitar sound to listen to it more clearly while suppressing other instruments. Once you become confident, now you want to play along with the song by suppressing the original guitar solo while keeping other instruments intact. Of course, usage of remixing is not limited to the practice sessions: one may just want to adjust each instrument’s volume to re-create a favorite balance among musical sources.
A straightforward approach to the remixing problem is to separate out the sources first and then manipulate them accordingly. While this is doable in theory, it only works well if the source separation part is near perfect.
Let’s see an example.

Suppose there is a mixture of two sources, guitar and drums. Unless source separation is perfect, the reconstructed guitar source can be decomposed into three parts: the contribution of the ground-truth guitar, interfering source (drums in this case), and artifact. The remaining interference of the other source indicates that the separation job was not perfect; as a result, we can hear some drum attacks from the guitar reconstruction. Meanwhile, the artifact is more about the behavior of the source separation algorithm and is problematic as well—it’s a dummy unwanted signal generated during the separation process, something that wasn’t originally there in the input mixture. For example, a very nicely separated source can still contain some annoying hissing artifact sound that seriously degrades the audio quality, although it’s out of the blue. Ditto for the drum reconstruction case. The tradeoff caused by this kind of decomposition has been commonly addressed in source separation systems to better assess the quality of separation 1.
Due to the imperfect separation, the separation-followed-by-remixing process can suffer from unreliable outcomes. For example, if the user wants to boost the volume of the drums by a certain amount, say 6dB, then the gain control applied to the reconstructed drums boosts not only the ground-truth drums component but the other unwanted components, interference and artifact (the third row in the figure above). As a result, the remixed drums’ volume is not as loud as the user wanted because the gain was applied to the interfering source as well. Likewise, depending on the proportion of the interference, which is unpredictable, the same amount of gain control can produce varying results. Not a great user experience. In addition, the artifact component will be boosted as well, which can worsen the perceived audio quality.
Instead of the naïve source separation-based solution, we envision a system that somehow bypasses the separation step and performs remixing directly. Or, at least, we could still employ a separation module internally, but separation is done only implicitly so that the system has a chance to deal with the artifact and interference for an optimal remixing result.
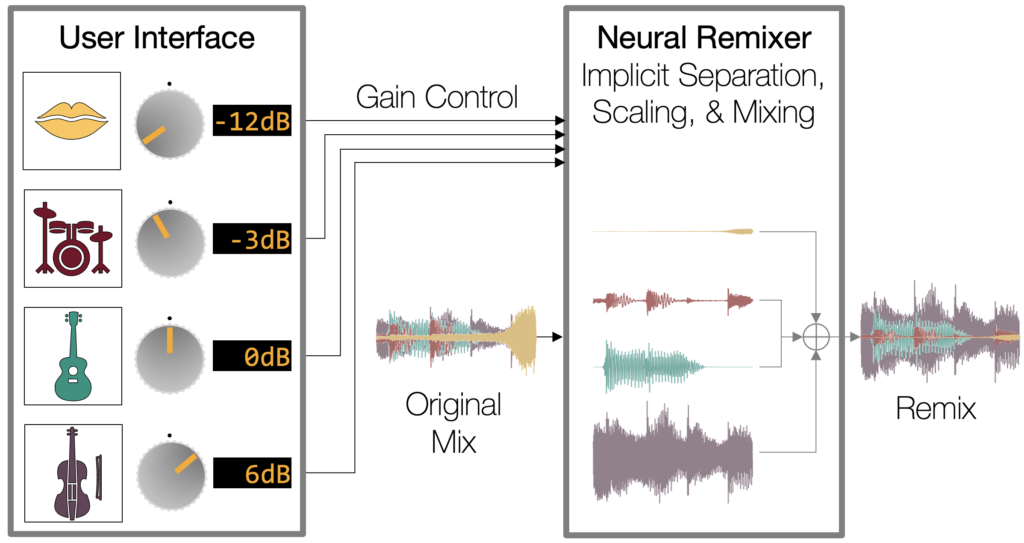
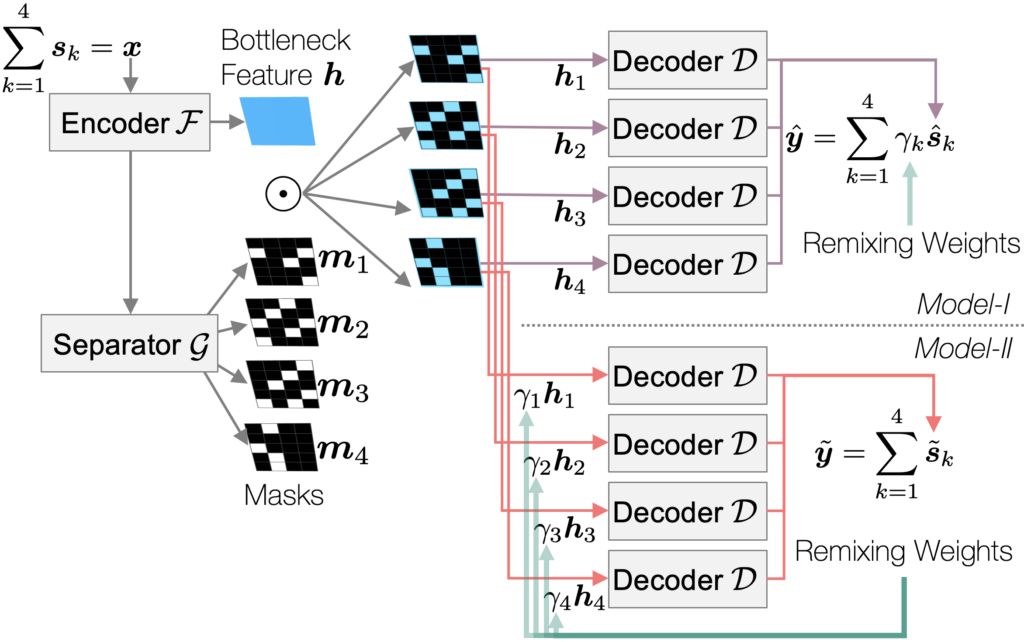
So, how does it work? Here, we present our deep learning model that performs end-to-end neural remixing. Basically, the idea is to train a neural network system that receives an auxiliary gain control from the user for each (hidden) source, instructing how to manipulate them. The gain control is used to construct a ground-truth remixture target during training, which instructs the model to produce the remixture directly. Although this could be implemented as a neural network that directly learns the mapping between the original mix and remix, in practice, we found that performing source separation, at least internally, is helpful.
We investigated two use-cases of the gain control during training: to formulate the target remix and to condition the source-specific latent representation of the source separation model. We claim that it is an e2e remixing model because the source separation model is encapsulated in the remixing system as a component. The separation module is now aware of the remixing target and acts accordingly: it may try to reduce artifact instead of trying too hard to do a better separation; it may adaptively boost the reconstructed instrument more than the user instructed if it is not confident about the interference removal; it may not try to do any source separation at all if the user’s gain control is near zero for all instruments.
Sound Examples
We found that the proposed remixing method tackles the interference-artifact tradeoff more effectively. Our results suggest that the proposed models (both Model-I and Model-II) are better in reconstructing the target remixture with less artifacts. It is prominent that the performance gap between ours and the baseline source-separation-followed-by-remixing method is larger if the gain control amount is moderate, where the baseline’s source separation effort is somewhat pointless.
Boosting the vocals
Boosting the drums
Boosting the bass guitar
Boosting “the other” sources
No changes to the sources
Paper
More information and details can be found in our paper:
Haici Yang, Shivani Firodiya, Nicholas J. Bryan, and Minje Kim, “Don’t Separate, Learn to Remix: End-to-End Neural Remixing with Joint Optimization,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, May 22-27, 2022 [pdf, code].
Source Codes
https://github.com/haiciyang/Remixing
ICASSP 2022 Virtual Presentation
- E. Vincent, C. Fevotte, and R. Gribonval, “Performance measurement in blind audio source separation,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 4, pp. 1462–1469, 2006.[↩]
- Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019.[↩]