For the general introduction to personalized speech enhancement (PSE), please read this article: Personalized Speech Enhancement.
Introduction
The fundamental difference between the specialist concept used in PSE and the general-purpose speech enhancement (SE) system is that the former wants to adapt to the specific test-time user and his/her acoustic environment. This kind of adaptation, in theory, is doable by setting up an optimization task that uses a good amount of training pairs for input and target: the noisy speech and its clean version.
In practice, it is not that simple because it means that the system has to ask for dry clean speech recordings from the users after the system is deployed. There are many reasons why the specific user’s clean speech is hard to acquire. For example, the users may not want to share their clean speech with the big tech company due to the privacy concerns. Even if they are eager to do so, they may lack the skills and facility to record their clean speech: they may think their recording is clean, but it might not be clean enough to be used as the optimization target.
From the system’s perspective, the test-time user’s noisy speech is relatively abundant compared to the clean speech. But, the noisy speech data is useless from the machine learning perspective unless we know the corresponding clean speech. So what should we do?
Data Purification
In this work, we came up with a data purification concept, which examines the noisy utterances and find out the parts that are clean enough. Then, what? We will only focus on those estimated clean areas as the target to perform a PSE training. This is based on the assumption that the so-called noisy speech utterances are not always noisy.
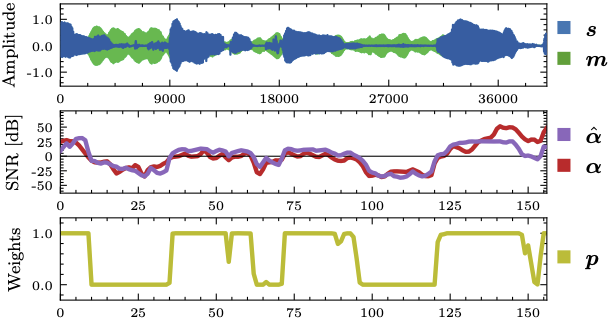
 : unknown clean speech of a particular test-time user.
: unknown clean speech of a particular test-time user. : unknown test-time interference.
: unknown test-time interference. : the ground-truth SNR values comparing and
: the ground-truth SNR values comparing and  : the estimated SNR values.
: the estimated SNR values. : weights derived from ; larger weights for cleaner samples.
: weights derived from ; larger weights for cleaner samples.To this end, we trained a speech quality estimator. For a short-period of time, if speech is much louder than the non-speech sources, then the SNR value must be high. The speech quality estimator basically listens to the signal and figures out if the signal is clean or not. The score ranges from  to
to  having zero as the case when the speech and non-speech sources are equally loud. In the figure above, for example, we can see that the speech signal has some soft area around 27000th sample, where the non-speech component is a dominant source. So, in the middle graph, we see that the corresponding ground-truth SNR value is very low. We can see that our speech quality estimator, a GRU network, can estimate the SNR values with a reasonable accuracy (the purple line for the values).
having zero as the case when the speech and non-speech sources are equally loud. In the figure above, for example, we can see that the speech signal has some soft area around 27000th sample, where the non-speech component is a dominant source. So, in the middle graph, we see that the corresponding ground-truth SNR value is very low. We can see that our speech quality estimator, a GRU network, can estimate the SNR values with a reasonable accuracy (the purple line for the values).
Pseudo SE: the Self-Supervised Learning Process
Using this SNR predictor, we selectively use these noisy utterances for self-supervised learning (SSL). Since SSL is to make the most use out of unlabeled data, which corresponds to noisy speech in our case, it means that we will come up with a pretext task that can train the SE model without knowing the ground-truth clean speech. To this end, we define our pseudoSE task that utilizes the noisy speech and the data purification process.
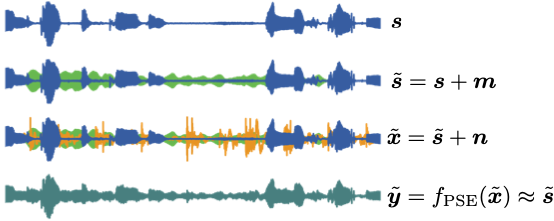
 here means the pseudo SE function, not a personalized SE model.
here means the pseudo SE function, not a personalized SE model.First, we assume that the test user’s clean speech is not known. Instead, we can acquire its noisy version  , which is the user’s speech contaminated by the unknown noise source , i.e.,
, which is the user’s speech contaminated by the unknown noise source , i.e.,  . From now on, the pseudo SE process will consider the premixture speech as the pseudo target speech. We add additional noise
. From now on, the pseudo SE process will consider the premixture speech as the pseudo target speech. We add additional noise  to the pseudo speech to form the final input mixture
to the pseudo speech to form the final input mixture  . Now we train an SE model, where works as if it’s a clean speech target.
. Now we train an SE model, where works as if it’s a clean speech target.
While the pseudo SE method itself should work to some degree as a pretext task, and it is a legitimate SSL method as it does not require any clean speech. However, as for the frames heavily contaminated by the unknown premixture noise (the green waveform in the figure above), the effectiveness of the pseudo SE process is not guaranteed, as it learned to estimate noisy speech rather than the clean speech.
Our main argument in this paper is that this pseudo SE-based SSL process can be improved by harmonizing the data purification concept. When we train the pseudo SE function , instead of treating all regions equally, we can focus more on the originally clean areas where the activity of is minimal, while is active. Once again, this is not the kind of knowledge known to the system, so that’s why we need to estimate the speech quality. Then, when we compute the time-domain sample-by-sample loss during pseudo SE training, we can apply the weights induced from the SNR predictor and ignore the samples that might be contaminated by the premixture noise source already. You know, the loss is basically based on the discrepancy between the estimated pseudo source  and the pseudo source . Then, we can write,
and the pseudo source . Then, we can write,
![\[\mathcal{L}=\sum_t p_t \mathcal{E}(\tilde{{y}}_t, \tilde{{s}}_t),\]](https://minjekim.com/wp-content/ql-cache/quicklatex.com-bca6d5be12627fc3b930576d51e735d8_l3.png "Rendered by QuickLaTeX.com")
where  denotes the sample-by-sample weights computed from the SNR prediction. For example, if
denotes the sample-by-sample weights computed from the SNR prediction. For example, if  is too noisy, the loss computed from that sample isn’t reliable. In that case, the SNR predictor will say that the SNR of is low, and so is , accordingly. In this way, the pseudo SE pretext task can use purer data more than the less reliable speech signals.
is too noisy, the loss computed from that sample isn’t reliable. In that case, the SNR predictor will say that the SNR of is low, and so is , accordingly. In this way, the pseudo SE pretext task can use purer data more than the less reliable speech signals.
Experimental Results
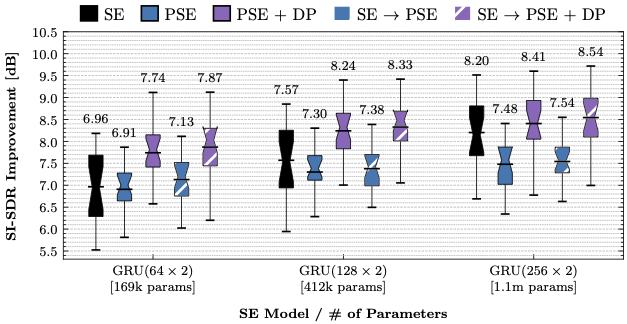
Our results show that pseudo SE itself (blue boxes) is not that meaningful due to the fact that it relies on the noisy speech as the pseudo target. Unless the pseudo target happens to be clean enough, it can’t compete with a generalist model trained from arbitrary training speakers and noise sets (black boxes). Our proposed data purification (DP) process can greatly improve the quality of noisy speech data and leads to a significant performance improvement (purple boxes). As always, the improved performance on small models means that personalization serves as a model compression tool.
The Paper
For more details, please check out our Interspeech 2021 paper1.
A Short Overview Talk
Source Code
https://github.com/IU-SAIGE/pse-snr-informed
This material is based upon work supported by the National Science Foundation under Grant No. 2046963. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
- Aswin Sivaraman, Sunwoo Kim, and Minje Kim, “Personalized Speech Enhancement through Self-Supervised Data Augmentation and Purification,” in Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Brno, Czech Republic, Aug. 30 – Sep. 3, 2021 [pdf][↩]