The spatial image of a music source is an essential feature in the stereophonic music listening experience. An extreme case would be “Yellow Submarine” by The Beatles, where all the vocals are completely on the right channel for some reason. But, most of the time, the main vocals are at the center of the stereo, which is information useful for vocal source separation1. Sometimes in live recordings, the spatial location of the musical instruments can be mapped to the actual location of the sources at the stage (as in this case).
So, we have been thinking about how to use this spatial information in music source separation. A naïve approach could be to assume that the source of interest is with a fixed location throughout the entire song as in the vocal source separation case, but we know that it doesn’t always work. Instead, we formulated the problem as an informed source separation task2, where the source separation system benefits from the auxiliary information about the source’s spatial location. Then, the remaining question is “where do we get the information from?“
Here, we assume that the user may want to interact with this source separation process—they are eager to do better source separation so they listen to the music carefully and provide some guidance to the system as to which direction to focus on to extract sources from. This kind of interactive source separation is not a new idea. For example, the users can be asked to scribble on the 2D image representation of the song (a.k.a., spectrogram) to extract out a source of interest3. This time, we focus on spatially informed music source separation, which we name SpaIn-Net.
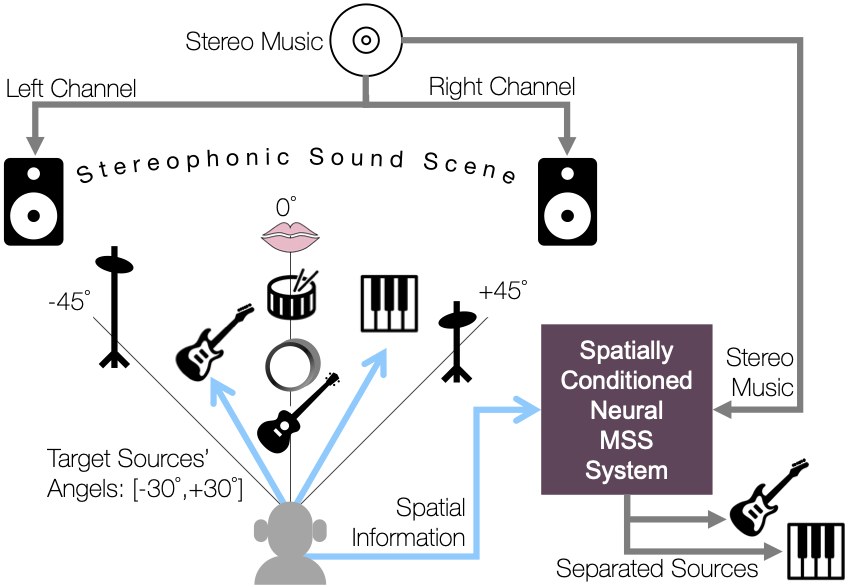
In the figure, for example, the user recognizes the location of the two sources of interest, guitar and piano, and gives that information to the neural network-based music source separation system. As a deep learning model, of course, the system can be trained to do a certain level of music source separation without this additional information, but our argument is that the performance would be better with the directionality information. A good example would be when there are two otherwise confusing instruments that are positioned differently in the stereo field (e.g., two rhythm guitars on the left and right channels, respectively).
The user interaction part gives a unique touch to our project: although using spatial information for source separation has been explored in the literature quite extensively4, we investigate the robustness of the SpaIn-Net when the user input is not accurately pointing to the direction of the sources—by deliberately allowing some error.
Based on one of the state-of-the-art music source separation systems, Open-Unmix + CrossNet (XUMX)5, we explored various conditioning mechanisms ranging from simple concatenation to positional encoding and AdaIN. Our fully-controlled synthesized experiments on the Slakh dataset6 verified that the spatially informed music source separation is a valid concept even if the user’s input is inaccurate.
Sound Examples
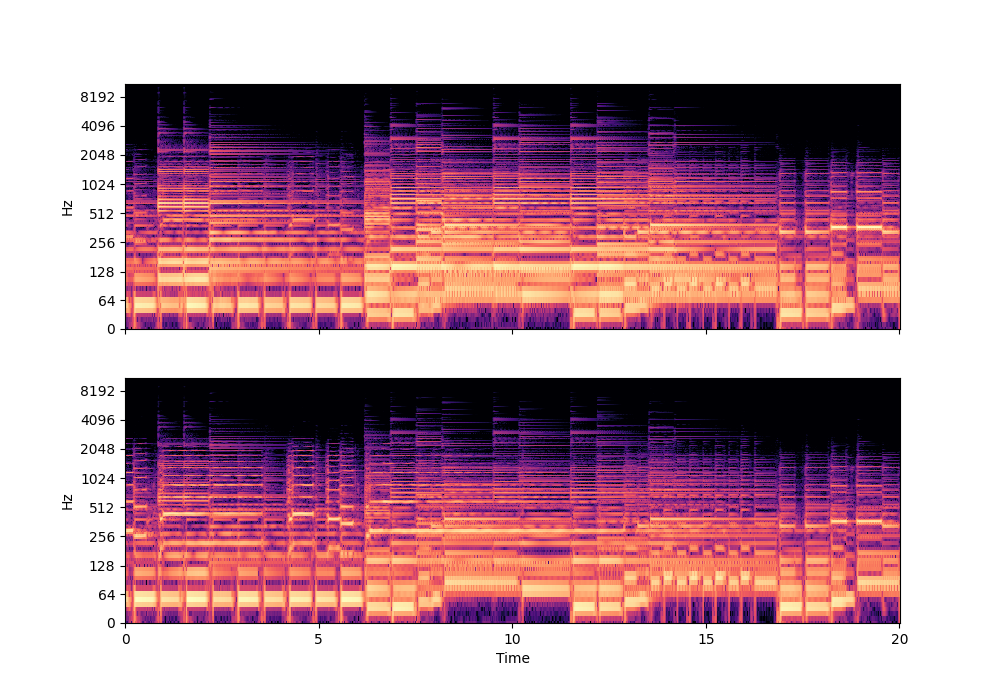
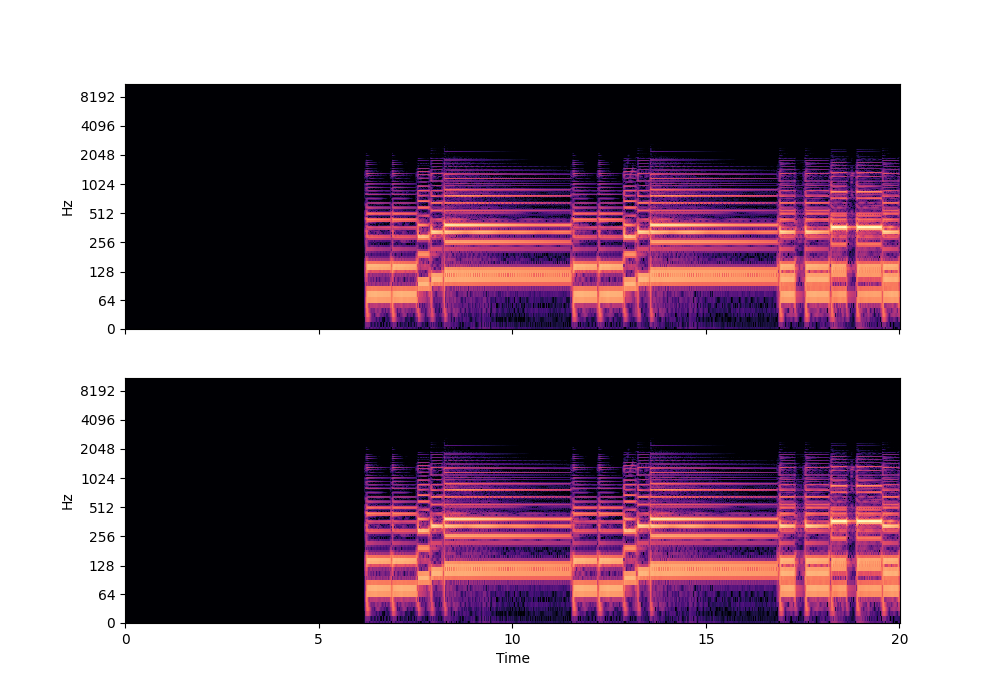
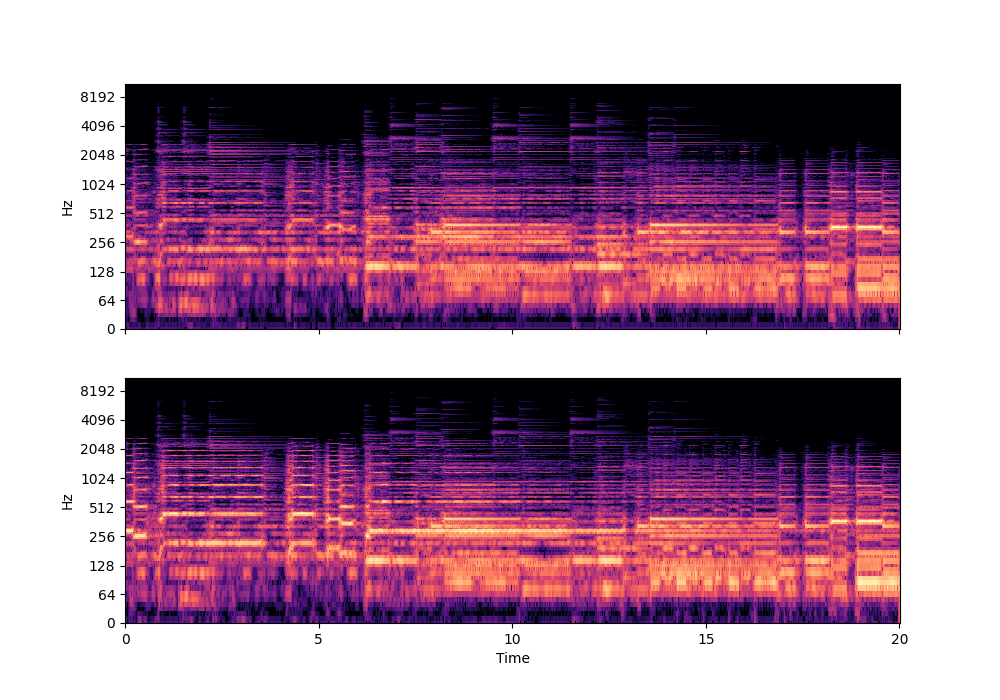
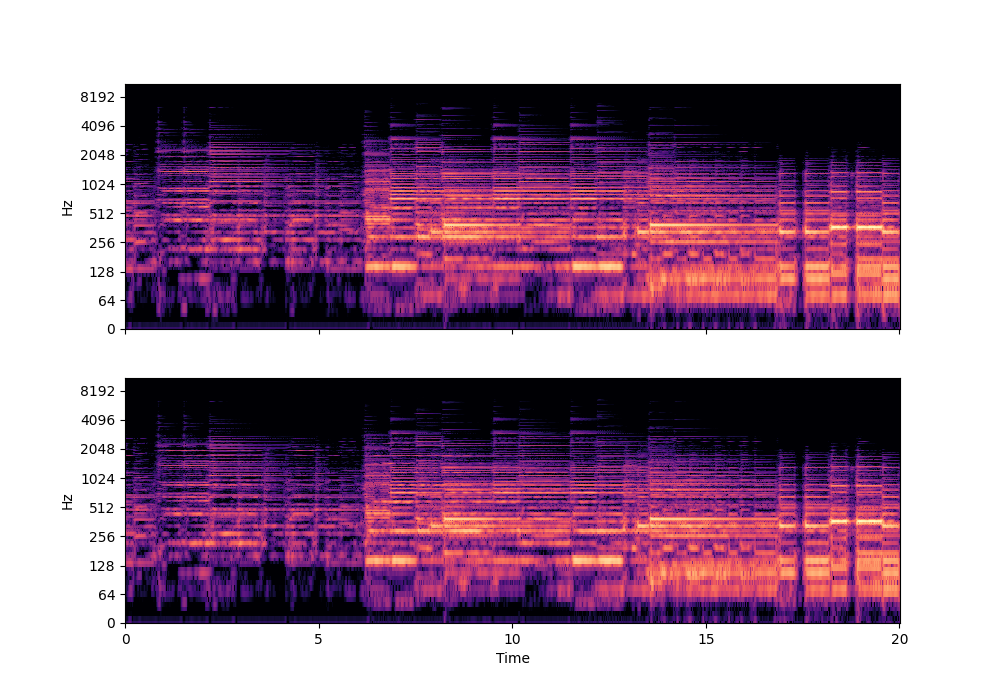
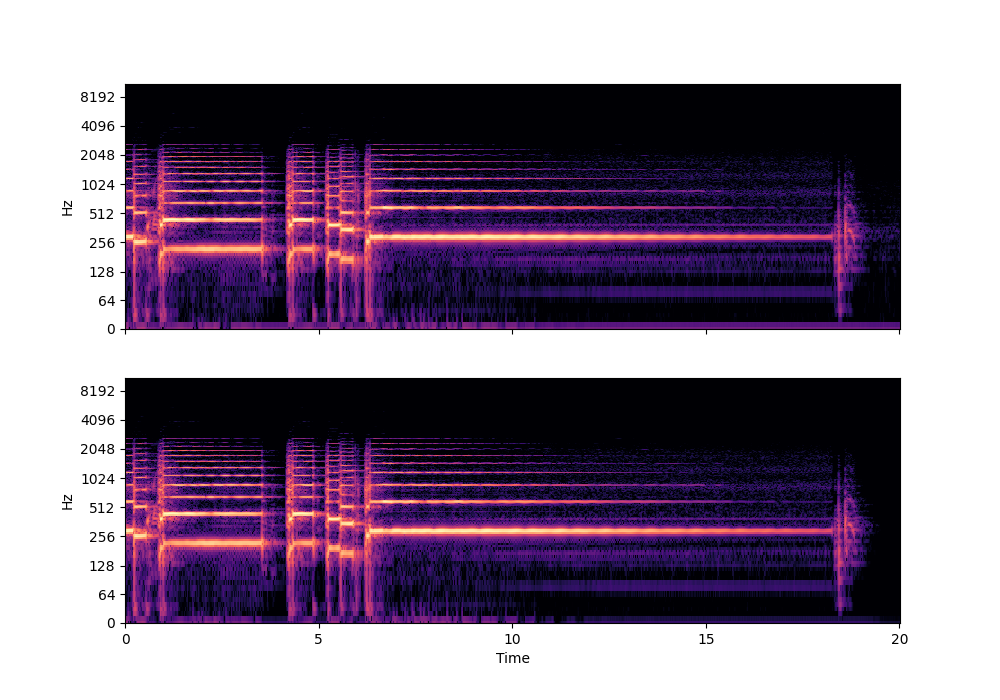
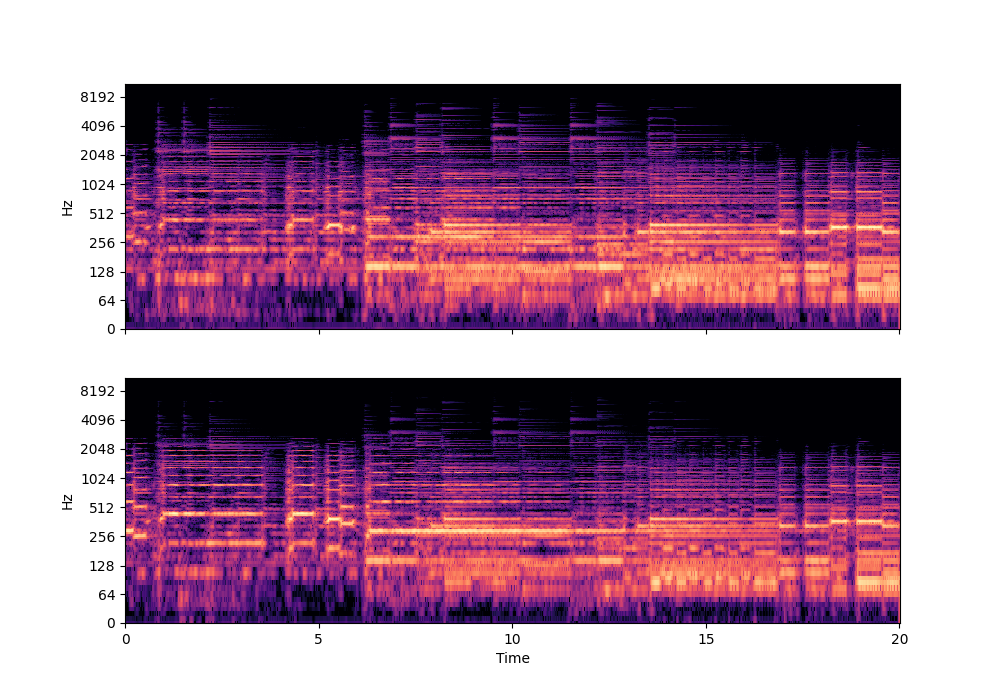
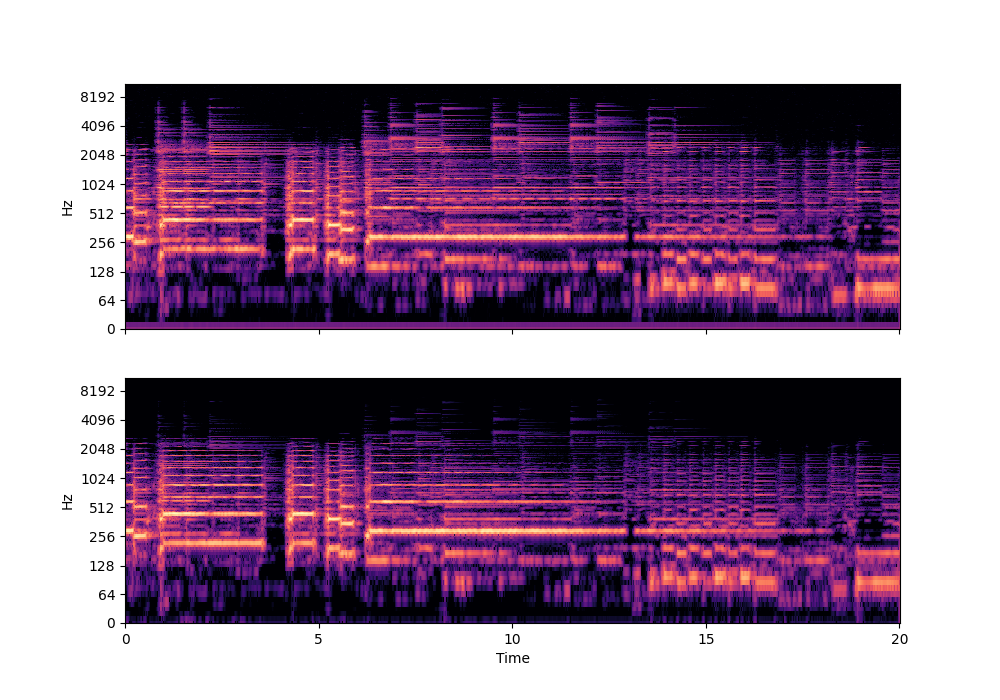
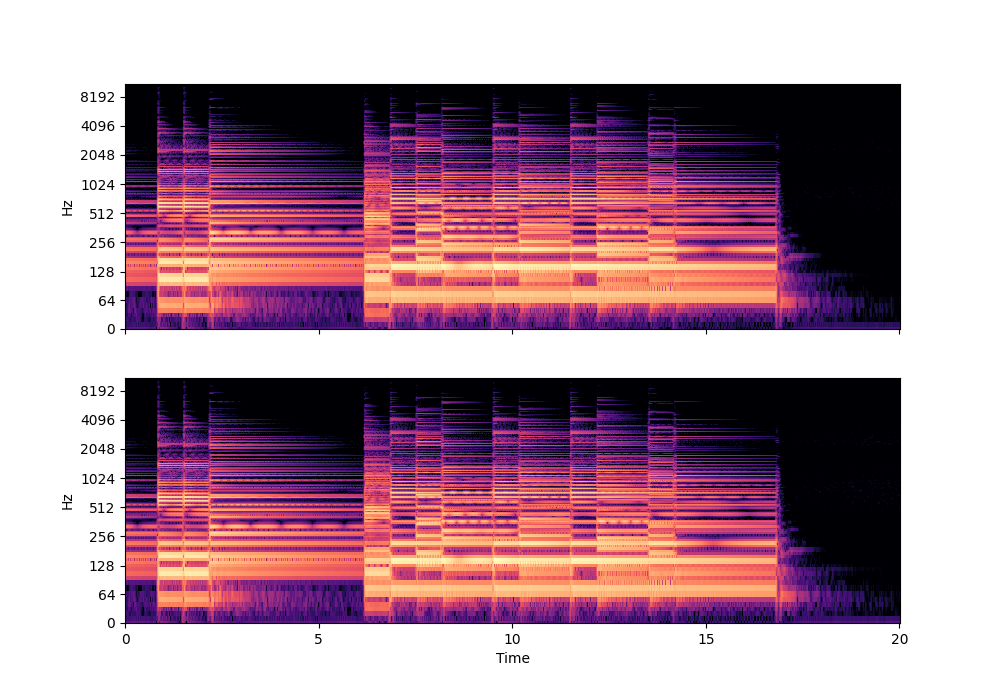
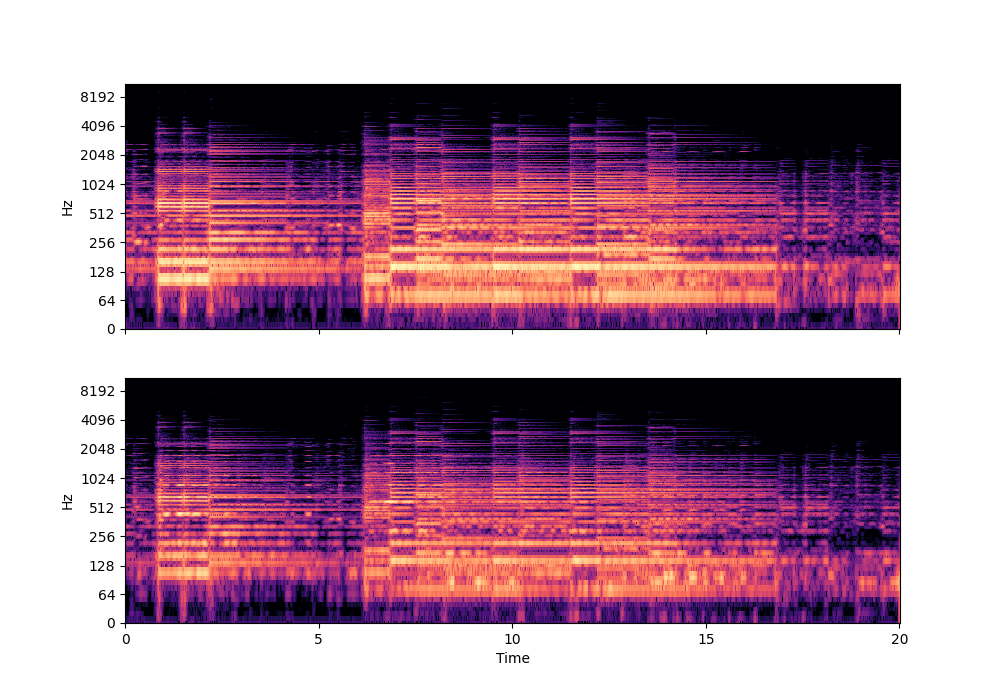
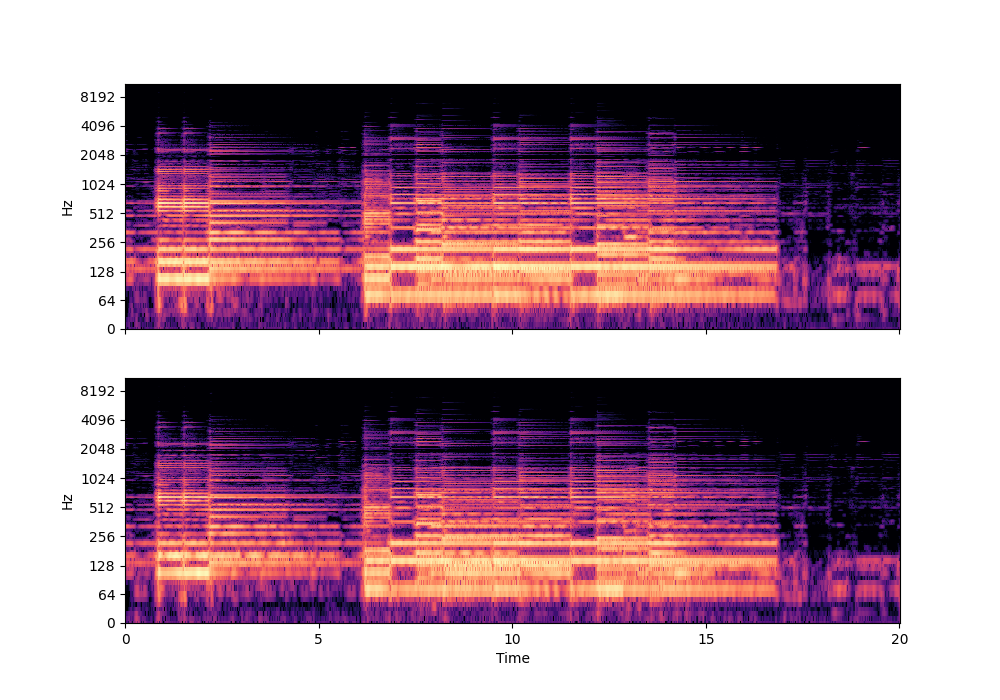
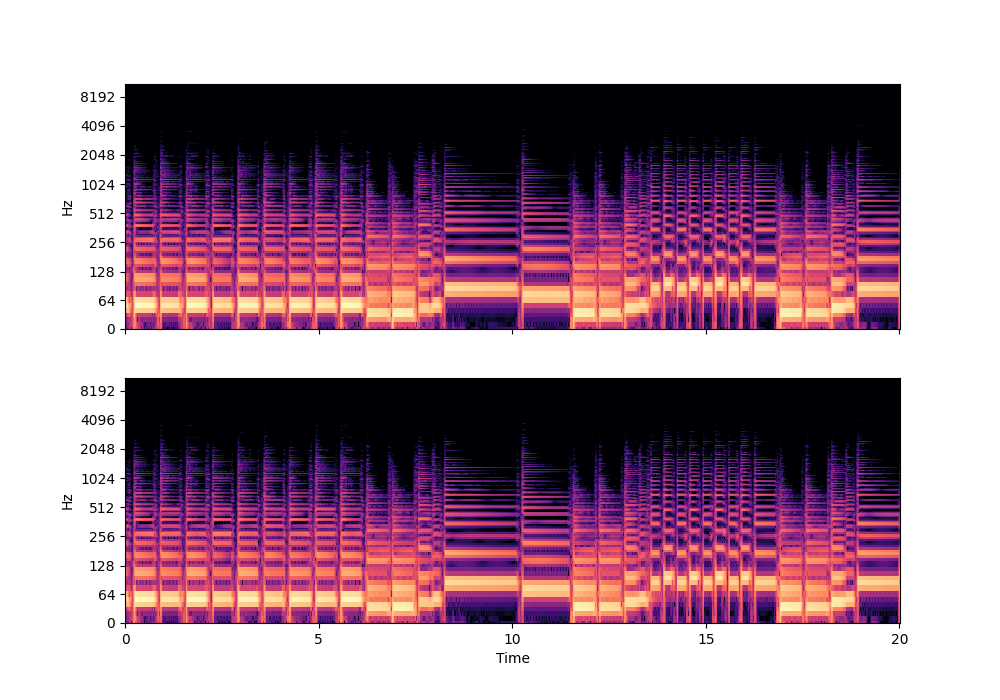
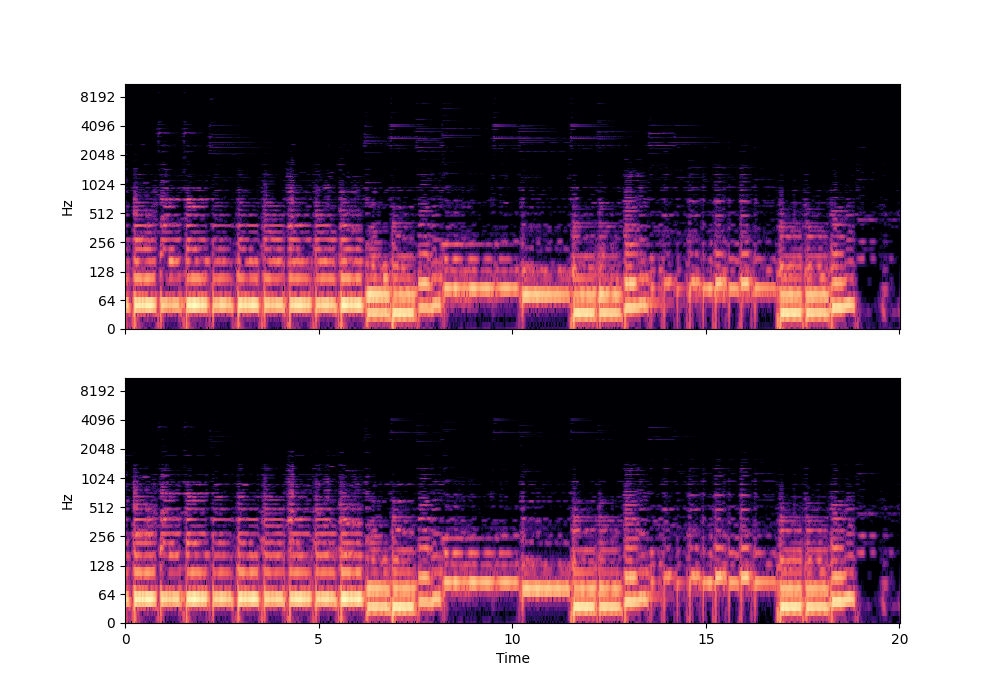
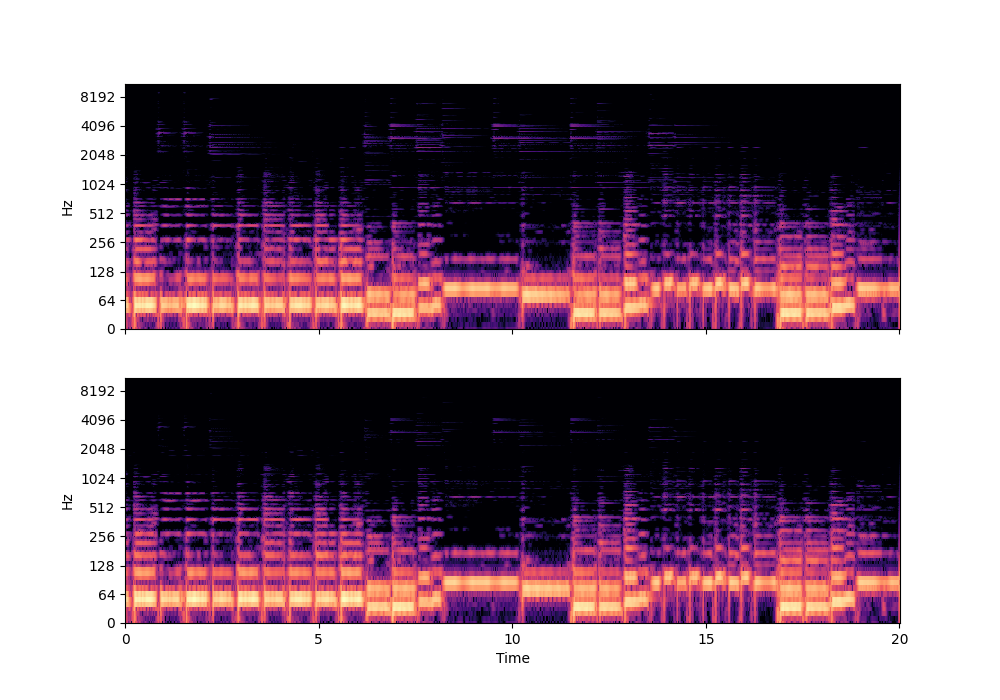
In this rather challenging example with two guitars, we can see that Recovered Guitar 1 and 2 from the baseline system (the XUMX system with no spatial conditioning) are somewhat similar to each other, showcasing the baseline’s confusion. On the other hand, the guitar separation results from the proposed SpaIN-Net are significantly better.
For more details please find our paper7. We also opensourced the project8.
Paper
Darius Petermann and Minje Kim, “SpaIn-Net: Spatially-Informed Stereophonic Music Source Separation,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, May 22-27, 2022 [pdf, code]
Source Codes
https://github.com/darius522/spain-net
ICASSP 2022 Virtual Presentation
- Minje Kim, Seungkwon Beack, Keunwoo Choi, and Kyeongok Kang, “Gaussian Mixture Model for Singing Voice Separation From Stereophonic Music,” in Proceedings of the Audio Engineering Society 43rd International Conference (AES Conference), Pohang, Korea, Sep. 29 – Oct. 1, 2011. [pdf, demo][↩]
- A. Liutkus, J.-L. Durrieu, L. Daudet, and G. Richard, “An overview of informed audio source separation,” in International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), 2013.[↩]
- http://isse.sourceforge.net[↩]
- Z. Chen et al., “Multi-channel overlapped speech recognition with location guided speech extraction network,” in IEEE Spoken Language Technology Workshop (SLT), 2018.[↩]
- R. Sawata, S. Uhlich, S. Takahashi, and Y. Mitsufuji, “All for one and one for all: Improving music separation by bridging networks,” in Proc. of the International Society for Music Information Retrieval Conference (ISMIR), 2020.[↩]
- http://www.slakh.com[↩]
- Darius Petermann and Minje Kim, “SpaIn-Net: Spatially-Informed Stereophonic Music Source Separation,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Singapore, May 22-27, 2022 [pdf, code].[↩]
- https://github.com/darius522/spain-net[↩]