For the general introduction to personalized speech enhancement (PSE), please read this article: Personalized Speech Enhancement.
Our dream is to develop a universal speech enhancement system that can deal with all the different kinds of corruption and variation a speech signal can go through: speaker-specific characteristics, reverberation, interfering noise, cross talk, band-pass filtering, clipping, etc. We know that the hypothetical universal speech enhancement system might be a gigantic deep neural network (DNN) with a complicated network structure. But, what if it’s easier to train a smaller and simpler system (e.g. a shallower and narrower DNN), which is specialized for removing only one kind of artifact? What if a few such systems are already available, and the best result among them is comparable to what we want from the hypothetical universal speech enhancement system? If there is a method that can choose the best model out of the candidate specialized systems, we can combine them to build the universal speech enhancement system.
This approach is beneficial in a lot of sense under certain conditions. First, we can reuse all those already-trained DNNs as our modules instead of training the all-purpose gigantic DNN from scratch. If the participating modules are DNNs with a simpler network topology and are easier to train, we can build the desired universal speech enhancement system easier and faster. Second, the proposed approach is more scalable. If the proposed system needs to handle a newly observed type of corruption, we can quickly learn a module specialized for the new training examples, and add it to the pool of candidates.
The main goal of this work is to devise a moderator, whose job is to choose the best module for an unseen test mixture. Although potentially this job could be done by a classifier1 2, we took another path. The main reason is that the discriminative classifier is not very scalable to the new examples. Instead, we trained an AutoEncoder (AE) by using pure speech spectra only. As an AE’s training goal is to minimize the error between the input and the output, the AE we trained using clean speech should produce clean speech for a clean input speech. We use this AE reconstruction error as a measurement to assess the quality of all the module-specific intermediate speech enhancement results. The basic idea is this: (a) we feed the intermediate modular outputs to the speech
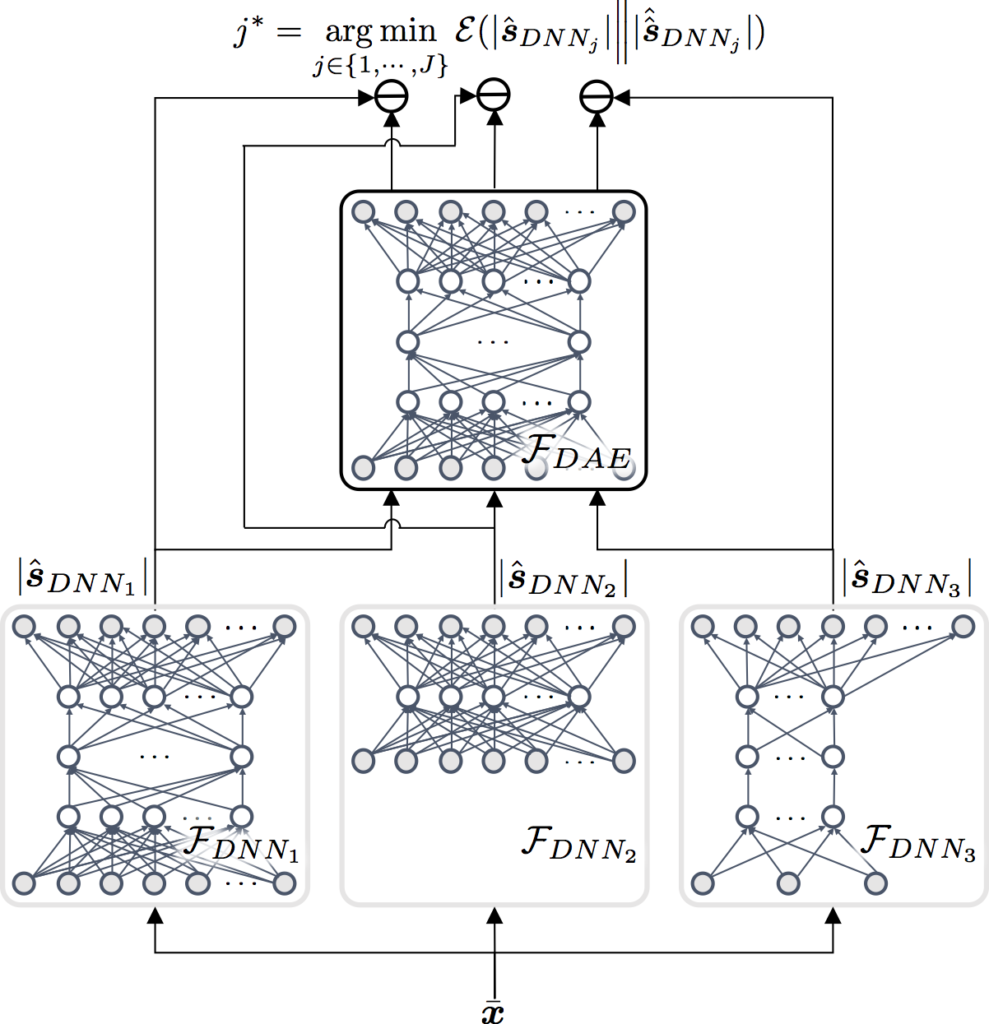
The performance of this model selection mechanism is great. The AE is very successful at selecting the best module (note that it deals with test signals without any ground-truth targets). we call this a Collaborative Deep Learning for speech enhancement, as we can harmonize whatever DNN for speech enhancement, if its job is to predict cleaned-up speech. Check out the audio examples below when the top AE makes the best selection in comparison to the worst potential choice.
Check out our ICASSP 2017 paper on collaborative deep learning3 for more details.
There are a couple of drawbacks in the proposed system. First, it has to run all the specialist models for a comparison, while a classifier-based system can run the classifier first to figure out which specialist to use. But, reliance to a classifier limits the scope of the system to pre-defined subdivision of the problem. So, there’s pros and cons. For more about the classifier-based systems, check out our papers about sparse mixture of local experts1 2.
- Aswin Sivaraman and Minje Kim, “Sparse Mixture of Local Experts for Efficient Speech Enhancement,” in Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, October 25-29, 2020. [pdf][↩][↩]
- Aswin Sivaraman and Minje Kim, “Zero-Shot Personalized Speech Enhancement Through Speaker-Informed Model Selection,” in Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, Oct. 17-20, 2021 [pdf].[↩][↩]
- Minje Kim, “Collaborative Deep Learning for Speech Enhancement: A Run-Time Model Selection Method Using Autoencoders,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, March 5-9, 2017. [pdf][↩]