For the general introduction to personalized speech enhancement (PSE), please read this article: Personalized Speech Enhancement.
Sparse Mixture of Local Experts (Interspeech 2020)
One way to efficientlytackle speech enhancement (SE) is to subdivide the overly large SE problem into smaller sub-problems. The SE problem is indeed a very big concept: a proper SE system is expected to handle various test-time conditions that are not known during training, such as the trait of the speaker, peculiar room acoustics, unique interfering sources, etc. It is a challenging generalization problem, calling for a big model trained from big data, which is a setup known to generalize well. The issue is, you know, we don’t like big models in SAIGE because they don’t work in small devices.
What’s known in the SE community is that if there is a local expert that is specifically trained to solve a subset of the original problem, then we should go for it1. For example, “if we know that the test speaker is a male” and “if there is a specialist model trained only using male speakers,” the specialist model is more likely to achieve a better performance than a gender-agnostic generalist model (once the two have a similar model capacity). In other words, it is also the case when both models achieve the same level of SE performance, the specialist model might be smaller, thus more efficient.
One caveat in this argument though is that the system has to know about the test signal as to which specialist it belongs to. How do we do that? Well, it’s a simple classification problem! If we pre-define all  sub-problems ahead of time, we can train a -class classifier, which is pretty straightforward. The classification problem itself is not too easy though, because it’s on the noisy signals rather than clean speech, but pretty much doable.
sub-problems ahead of time, we can train a -class classifier, which is pretty straightforward. The classification problem itself is not too easy though, because it’s on the noisy signals rather than clean speech, but pretty much doable.
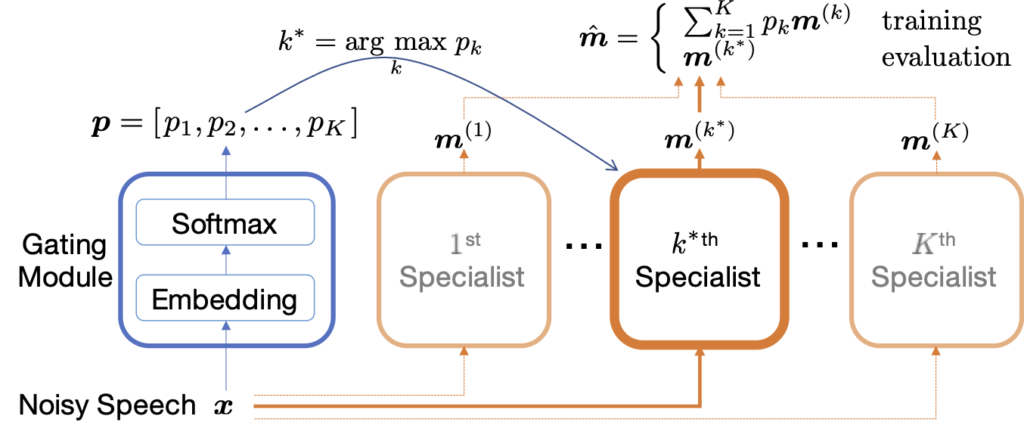
So the flow is like this. The noisy speech signal  is first fed to the classifier, which we call the gating module, following the convention of the famous mixture of local experts (MLE) framework2. As a classifier, it can produce the softmax probability over the pre-defined specialists, and the system, of course, chooses the specialist with the highest probability. This selection process is very important and differentiates our system from others: the system activates one and the only chosen specialist and runs the inference job on it, while the traditional MLE architecture and its SE adaptations do a convex combination of all specialists’ output using the probability values as weights. Likewise, ours is a sparse ensemble, because that way we can greatly reduce the run-time complexity by . For example, the shaded specialists in the overview diagram are never used for that input signal.
is first fed to the classifier, which we call the gating module, following the convention of the famous mixture of local experts (MLE) framework2. As a classifier, it can produce the softmax probability over the pre-defined specialists, and the system, of course, chooses the specialist with the highest probability. This selection process is very important and differentiates our system from others: the system activates one and the only chosen specialist and runs the inference job on it, while the traditional MLE architecture and its SE adaptations do a convex combination of all specialists’ output using the probability values as weights. Likewise, ours is a sparse ensemble, because that way we can greatly reduce the run-time complexity by . For example, the shaded specialists in the overview diagram are never used for that input signal.
Our proposed system is tested on two different subgrouping strategies based on the gender and noisiness, a.k.a. signal-to-noise ratio (SNR). For the latter, we divide the training set into four different categories with varying SNR levels: -5 (very noisy), 0, 5, 10 (mild noise condition).

 SNR levels to specify specialists
SNR levels to specify specialists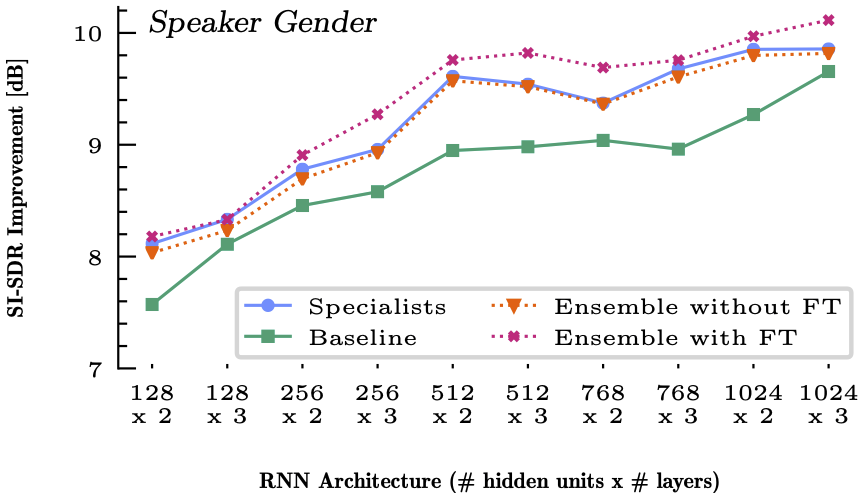
 genders to specify specialists
genders to specify specialistsThe results are exciting. From the figure (left), we see that the orange dotted line is almost always above the green line, meaning that, on average, the proposed model’s specialist works better than a generalist model with the same size. However, the gating module, or the classifier, isn’t making the perfect decision, and that’s why the orange dotted line is below the blue line, which is the results from the oracle model with a “perfect” classifier that always makes the correct decision. The right figure reinforces our analysis: there’s no big gap between the proposed model and the oracle model, because, this time, it’s an easy binary classification problem and our gating module’s performance is near perfect.
What about the pink dotted line? That’s the interesting one. First, we figured that the perfect classification is a myth, because, for example, there could be a male speaker whose pitch is high enough to suit better to the female-specific SE model than the male-specific one. Moreover, it might not be the best way to use the specialists if we have to pre-train them from each subgroup and freeze it. Instead, we could fine-tune the specialists so that they learn the optimal SE specialists considering the mistakes the gating module can make. You know what? We can also fine-tune the classifier by informing it of the final SE loss so that it can make a more advanced decision, something beyond the intermediate classification target. This fine-tuning step isn’t straightforward, as it involves differentiation over the “argmax” operation, which isn’t exactly differentiable. But, we made it work by using a few tricks. Eventually, as the graphs show, the final fine-tuned results surpass the oracle performance!
Note that we consider the proposed algorithm as zero-shot learning, because the personalization is done during the test time without using any clean speech data from the target speaker or knowledge about the test environment.
The Paper
For more details, please take a look at our paper3.
Presentation Video
Our Interspeech virtual presentation is available below, too.
Sound Examples
We also present some audio examples. The point here is that our proposed specialist network, although it’s less complex (512 X 2), can compete with a large generalist (1024 X 3).
Example #1
the proposed specialist (512X2)
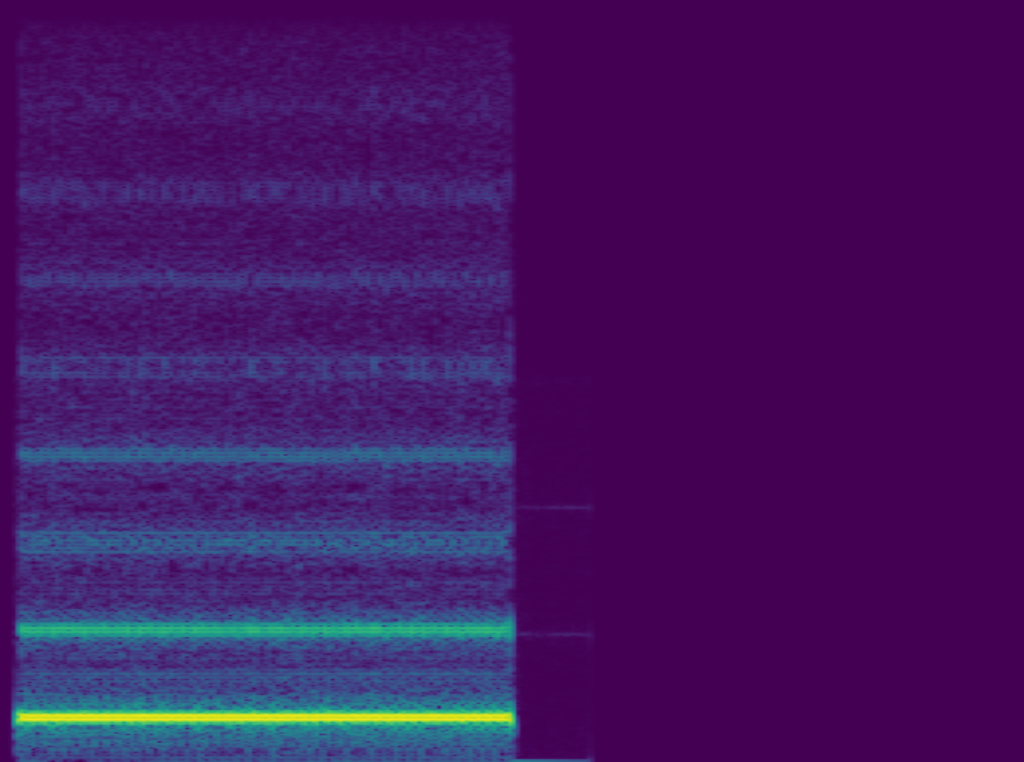
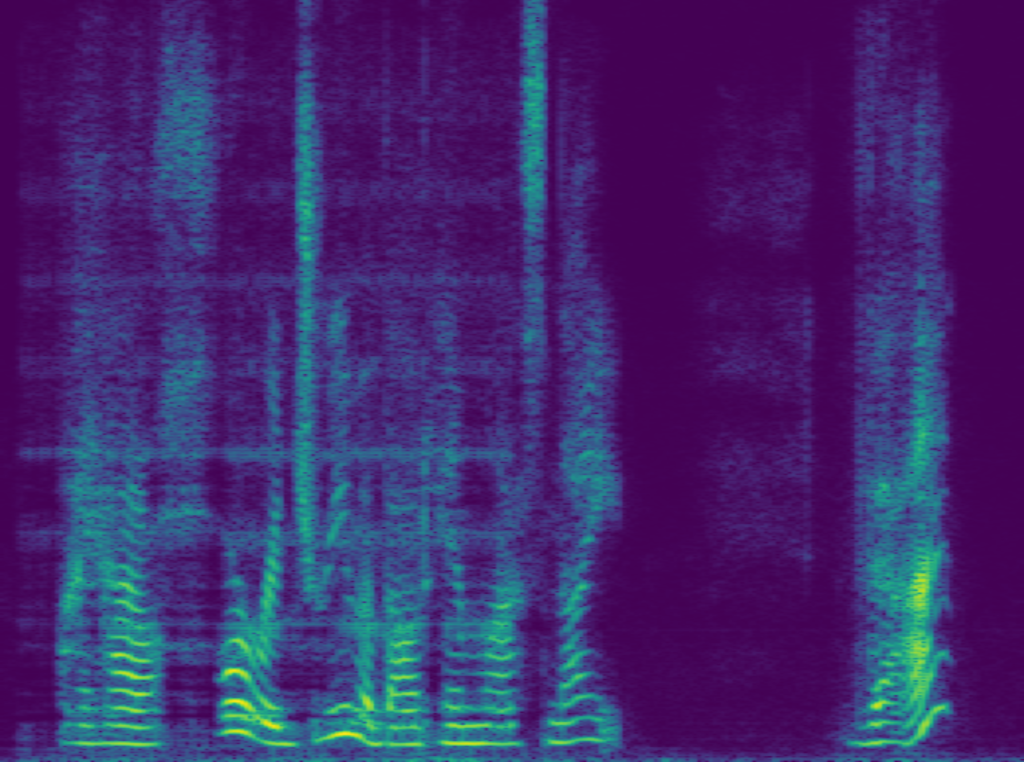
the small generalist (512X2)

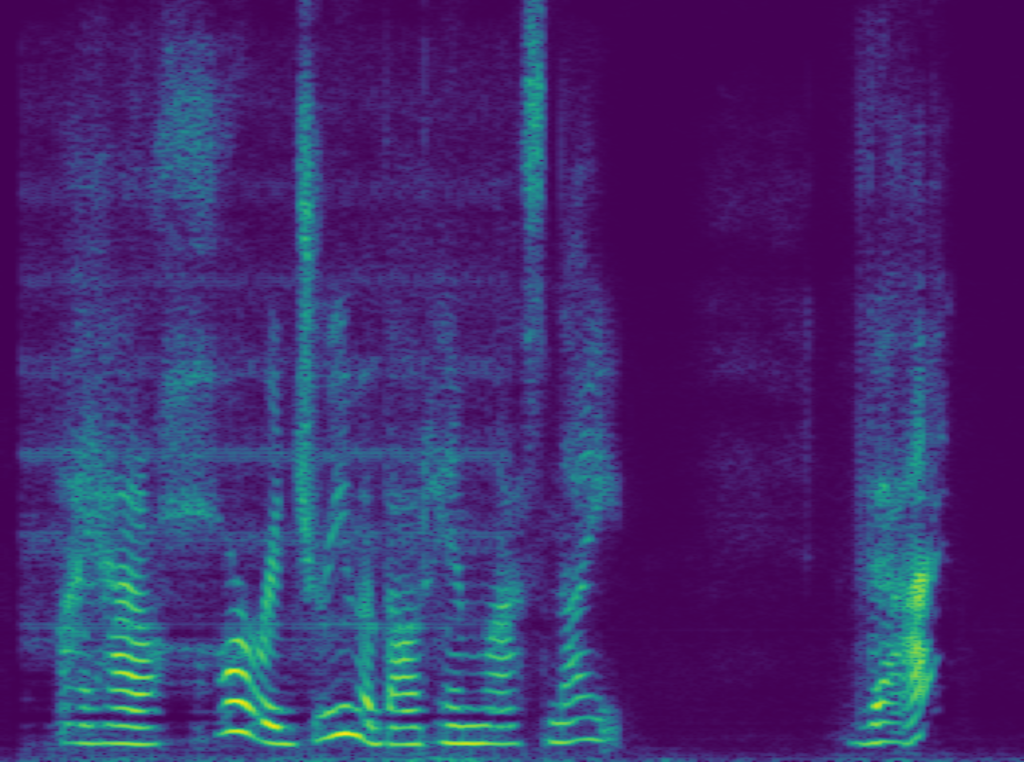
the large generalist (1024X3)
Example #2
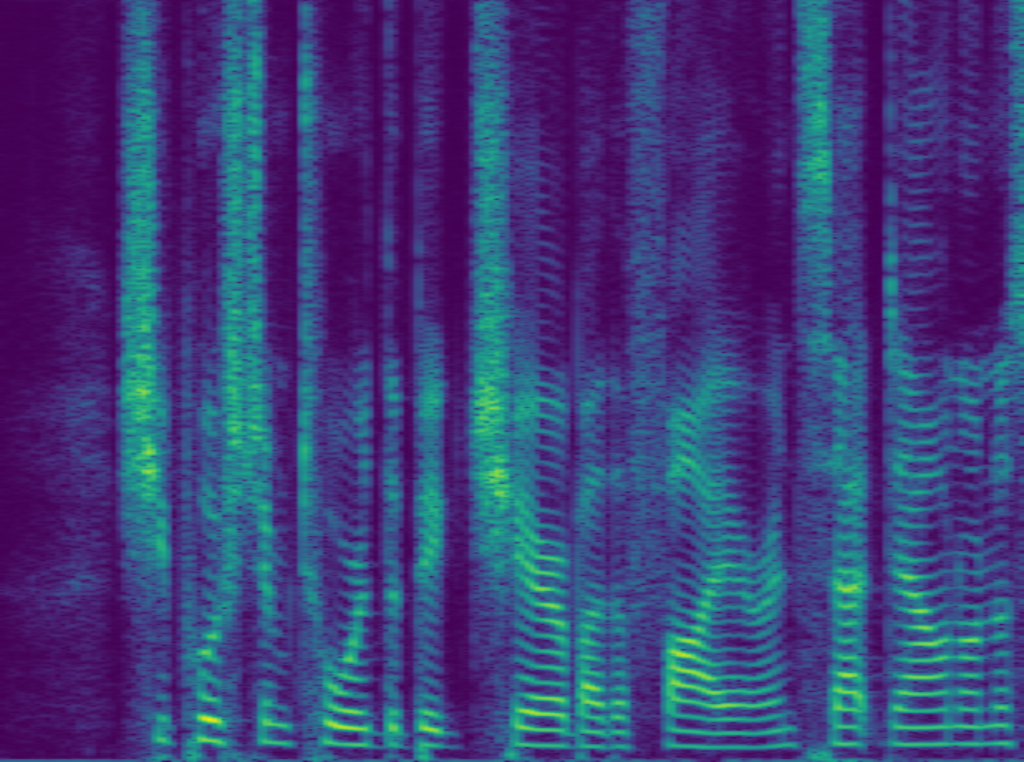
the proposed specialist (512X2)
the small generalist (512X2)
the large generalist (1024X3)
Source code
https://github.com/IU-SAIGE/sparse_mle
Speaker-Informed PSE (WASPAA 2021)
We admit that we have abused the term personalization so far, as the model adaptation algorithm we presented wasn’t about the “person,” although essentially the ultimate adaptation has to consider all the test-time environments. Anyhow, the Interspeech paper3 is missing the consideration about the speaker identity.
However, it is not trivial to utilize the speaker information for PSE. First of all, it may not make sense to employ too many specialists, because that’ll involve a bunch of never-used specialists in the system. Hence, even though we could collect many training speakers, it’s not a good idea to prepare a specialist per speaker. Instead, we need to somehow group the speakers into a manageable number of clusters.
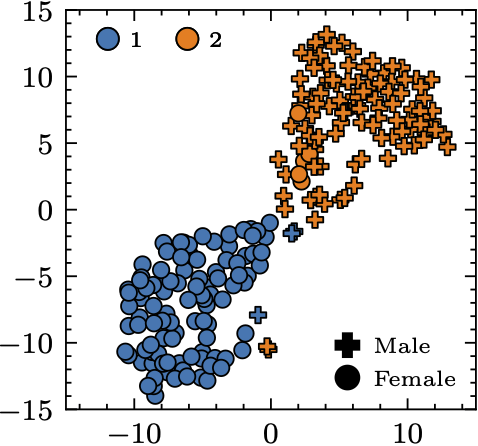
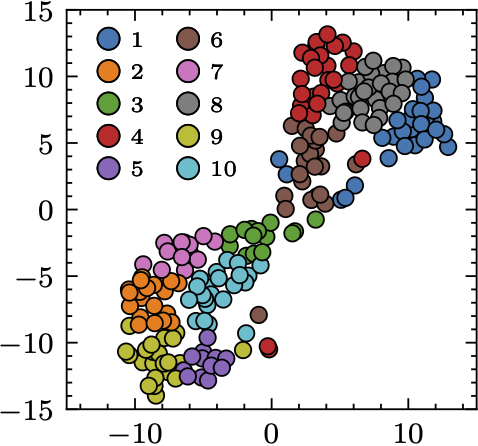
To this end, we first trained a Siamese network4 such that it predicts similar embeddings for the input noisy utterances that are from the same speaker and vice versa. Out of these embeddings, we performed K-means clustering to find out our initial subgroups. The assumption here is that the speakers that belong to the same cluster may share similar speech characteristics.
 .
.
 .
.What’s interesting from the result is that the clustering algorithm found a natural subgrouping strategy based on the gender, although the clustering process wasn’t informed of that kind of information. result is less intuitive because the figure doesn’t show if the speakers within the same cluster indeed sound similar. We will move on and use these clustering results to pre-train our specialists and gating module.

Once again, the results are exciting. We can see that all ensemble models with varying outperforms the baseline with the same model complexity (with a specialist). We also see that the fine-tuning improves the overall system performance. One significant comparison is between the black circled points: the one on the yellow line uses only 170K parameters, while the equally-performing baseline model (black line) is about 20 times larger (3.4M parameters).
To summarize, even though the models are not based on a well-defined subgrouping strategy, an unsupervised clustering approach is good enough to learn the effective subgroups, which lead to an effective and compact PSE.
The Paper
Check out our WASPAA 2021 paper for more details5.
Presentation Video
Our Interspeech virtual presentation is available below, too.
※ The material discussed here is partly based upon work supported by the National Science Foundation under Award #: 2046963. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
- M. Kolbæk, Z. H. Tan, and J. Jensen, “Speech intelligibility potential of general and specialized deep neural network based speech enhancement systems,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 1, pp. 153–167, Jan 2017.[↩]
- R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,” Neural Computation, vol. 3, no. 1, pp. 79–87, Mar. 1991.[↩]
- Aswin Sivaraman and Minje Kim, “Sparse Mixture of Local Experts for Efficient Speech Enhancement,” in Proceedings of the Annual Conference of the International Speech Communication Association (Interspeech), Shanghai, China, October 25-29, 2020. [pdf][↩][↩]
- J. Bromley, I. Guyon, Y. LeCun, E. Sa ̈ckinger, and R. Shah, “Signature verification using a “siamese” time delay neural net- work,” in Advances in Neural Information Processing Systems (NIPS), 1994, pp. 737–744.[↩]
- Aswin Sivaraman and Minje Kim, “Zero-Shot Personalized Speech Enhancement Through Speaker-Informed Model Selection,” in Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, Oct. 17-20, 2021 [pdf].[↩]