(Download Interspeech 2022 Tutorial Slides)
The outstanding development in modern AI has relied greatly on the improved modeling capacity. The deep learning models, for example, are effective in scaling up its approximation ability to a very complex mapping function. Hence, if there is a large enough, stongly-labeled, real-world training dataset available (good luck with that!), one can finally implement an AI model that can solve a real-world problem.
While we fully appreciate the advancement in deep learning, we would also want to share our thoughts about these large models trained from large datasets. There are technical and societal issues involved in this setup, that eventually lead us to questions about ethics of AI. Some examples are:
- Advanced AI models can only be developed in a costly industrial setup, deteriorating the accessibility of AI systems from the general public 1. This can mean that the necessary amount of computing resources and infrastructure are simply not affordable in academic environments or in underdeveloped economies.
- In addition, training a very large deep neural network is not environment-friendly. For example, training a large model in big computers requires a tremendous amount of electricity2.
- More importantly, large models can fail to work well with underrepresented social groups during the test time. The data-hungry nature of modern AI tends to involve a less representative but easy-to-collect generic dataset in its training. As data collection, processing, and annotation are the costly parts of developing an AI system, the common practice has been to collect as many data samples as possible and then to hire human annotators to label them. Hence, it is easy to overlook the social impacts of those large datasets until recently. For example, training from a large dataset often results in a biased model, which does not always generalize well to an unseen test environment. For instance, an underrepresented social group suffers from degraded performance, such as a face recognition system that recognizes the gender of darker-skinned female subjects with a 35 times higher error rate than light-skinned males 3. It turned out that it is due to the racial or gender inequity lying in big training datasets.
Our personalized speech enhancement (PSE) research technically addresses this issue by improving the imperfectly trained generic models’ performance for a specific user, i.e., through personalized AI running in the personal devices. Aside from the social implications mentioned above, there is an efficiency issue with the ordinary deep learning approach. In order to make deep models work for most of the test-time variations, we need to train a big model from a big data. Even if we can afford the cost of training such a model, deploying it to a small device is a different issue, because the big models do not fit the small devices. The redundancy within the big models comes from the fact that they are designed to cover all sorts of test-time user environments. As an alternative, personalized ML focuses on a specific user’s narrowly defined problem. For example, compared to a general-purpose speech enhancement problem that tries to address “all” test environments, the personalized problem targets a very small subset of the generic problem.
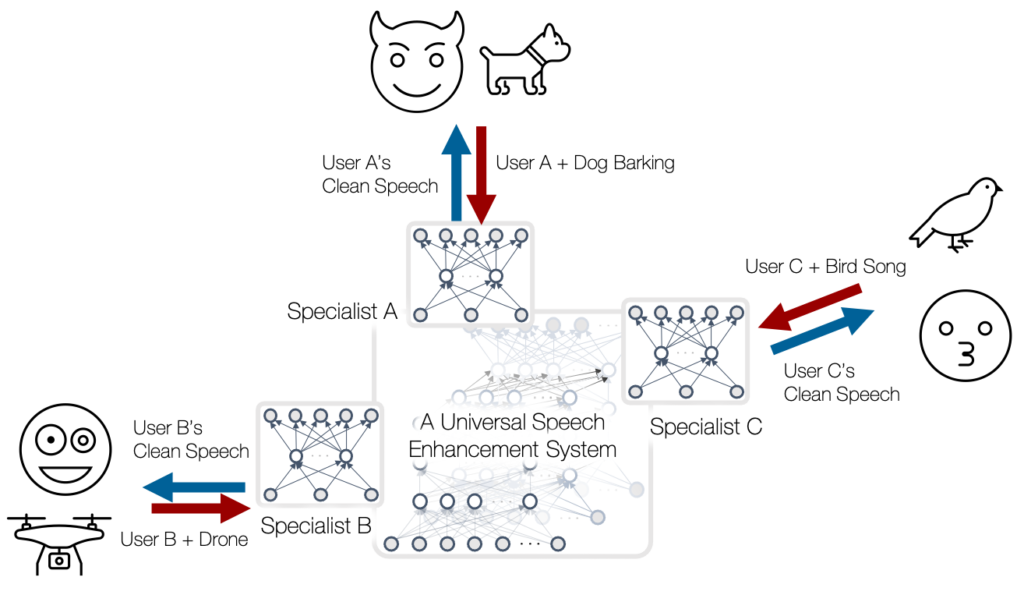
In developing the personalization algorithms, the key challenge is to minimize the use of personal data, because (a) personal data are often considered as private information (b) they can be collected only after the device is deployed, i.e., during the test time. Even if the users are relaxed about privacy issues and okay with sharing their clean speech, sometimes it is challenging to record one’s clean and dry speech due to the technical issues: maybe the room is too reverby and is with some fan noise while the user “thinks” it’s quiet. Probably the recording gears are not good enough either.
We are working on several personalization algorithms for speech enhancement. For now we focus on algorithms that adapt to the test environments requiring zero or as few as possible clean recordings from the users. The list of the sub-projects are as follows:
- Sparse mixture of local experts: For a given test signal, the system first asks a small classifier (i.e., a gating module) which sub-problem the test sample belongs to, and then runs the local expert specifically trained to solve that sub-problem. We found that this kind of approaches can result in a better performance and reduce model complexity. Since the system does not require any additional clean speech from the users, but just works with the noisy test speech, this can resolve the data efficiency issues as well. For more details, audio demos, and source codes, check out the project page here.
- Knowledge distillation: Once again, the system doesn’t need any clean speech from the users. But, this time, it asks a very large “teacher” network (e.g., up in the cloud) to perform the state-of-the-art level speech enhancement. Then, the small student model on the device finetune itself by learning from the teacher model’s results. Differently from the mixture of local experts method where the test-time adaptation happens by selecting the best local expert, the knowledge distillation approach does update the student model over time. You know what? In this way, the student model can sometimes exceed the teacher model! For more details, audio demos, and source codes, check out the project page here.
- Self-supervised learning and data purification: The PSE problem is defined as a self-supervised learning task. Based on the assumption that the test-time user’s noisy speech is not always noisy, the proposed data purification algorithm finds out the cleaner time frames and use them as if they are the clean speech target. In this way, we can formulate an optimization task having the purer speech frames as the pseudo target. Note that this method falls in the category of self-supervised learning, as we do not require clean speech target from the test-time users. For more details, audio demos, and source codes, check out the project page here.
This material is based upon work supported by the National Science Foundation under Grant No. 2046963. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
- D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. 2015. Hidden technical debt in machine learning systems. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS), 2503–2511.[↩]
- Strubell, E., Ganesh, A., & McCallum, A. (2020). Energy and Policy Considerations for Modern Deep Learning Research. Proceedings of the AAAI Conference on Artificial Intelligence, 34(09), 13693-13696. [↩]
- Buolamwini, J. & Gebru, T.. (2018). Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. Proceedings of the 1st Conference on Fairness, Accountability and Transparency, in PMLR81:77-91[↩]